Aktuelle und jährliche grafische Darstellungen der Stauinhalte der Harzer Talsperren
Nota bene: die folgende Seite enthält viele (> 50) statische, größere Grafiken, und sollte wenn möglich auf mindestens einem Tablet, besser noch einem grossen Monitor angezeigt werden. Smartphone bringt nix.
- 1. Die Harzer Talsperren und Trinkwasserversorgung
- 2. Auswertungen der Daten der Harzer Talsperren
- 3. Aktuelle und jährliche absolute Stauinhalte
- 4. Aktuelle und jährliche prozentuale Stauinhalte
- 5. Jahresvergleiche der Stauinhalte
- 6. Tabellarische Jahres-Bewertung
- 7. Aktuelle Tagesdifferenzen der Stauinhalte
- 8. Detaillierte Einzeldarstellungen aller sechs Talsperren
- 9. Statistische Vergleiche
- 10. Datenaufbereitung
- 11. Disclaimer
- 12. Kontakt
1. Harzer Talsperren und Trinkwasserversorgung
Die Trinkwasserversorgung im mittleren Niedersachsen wird hauptsächlich durch Grundwasser, aber auch durch einige Stauseen im Harz gesichert. So wurden zum Beispiel in 2013 für die öffentliche Wasserversorgung in Niedersachsen 557 Millionen m³ (ein halber Kubikkilometer etwa) Wasser gefördert, davon 86% Grundwasser und 11%, also 61 Mio m³ Wasser der Harzer Talsperren (Quelle: Niedersächsisches Ministerium für Umwelt, Energie, Bauen und Klimaschutz).
Die Grundwasserversorgung der Stadt Hannover wird durch das kommunale Unternehmen enercity mittels dreier Werke
- Wasserwerk Elze-Berkhof (Link zu Google Maps)
- Wasserwerk Fuhrberg (Link zu Google Maps)
- Wasserwerk Grasdorf (Link zu Google Maps)
Von den sechs durch die Harzwasserwerke GmbH verwalteten Harzer Talsperren führen Leitungen nach Wolfenbüttel, Braunschweig und Wolfsburg, nach Göttingen, Bad Gandersheim, Hildesheim, Lehrte, Neustadt, sogar nach Bremen, aber auch in das Hannoversche Umland, z.B. werden Teile der Vororte Laatzen, Rethen und Seelze über den Versorger enercity komplett mit Wasser aus den Talsperren versorgt (Quelle: Trinkwasseranalyse der Harzerwasserwerke auf enercity AG). Weiterhin wird das Wasser aus dem Harz mancherorts (z.B. im Süden Hannovers, im Wasserwerk Grasdorf) auch gefördertem Grundwasser beigemischt, da es generell sehr weich ist und hilft, zu kalkhaltiges Grundwasser zu enthärten.
Da Grundwasser eine teils sehr hohe Verweilzeit (siehe auch Grundwasserneubildung) aufweist, etwa 30 Jahre bei den drei genannten hannoverschen Grundwasserwerken, je nach Beschaffenheit des Untergrundes, der Tiefe des Entnahmepunkts und anderen Parametern zwischen mehreren Jahren, Jahrzehnten oder sogar Jahrhunderten, kann die "Latenz" (Zeitabstand Zufluss - Abfluss bzw. Entnahme, im englischsprachigen Raum als "groundwater recharge rate" bezeichnet) dieser Trinkwasserquelle als relativ hoch angenommen werden.
Die Latenz von Talsperrenwasser dagegen scheint weit geringer (abhängig von den Eigenschaften des Einzugsgebietes), nach einem kräftigen Regen können die Pegelstände von Stauseen und Flüssen innerhalb von Tagen signifikant ansteigen, manchmal sogar von Stunden. Verglichen mit dem Grundwasser verhält sich also Talsperrenwasser zeitlich weit dynamischer, und beinhaltet zudem eine in Maßen steuerbare Komponente: die Abgabe von Stauwasser in den weiteren Flusslauf.
Seit Juli 2017, der hier auffällig regenreich war, interessierte mich, welche Auswirkungen Wetterphänomene auf die Talsperren, und damit auf die lokale Trinkwasserversorgung haben. Dazu begann ich, die täglichen Wasserstandsdaten der Harzer Talsperren zu beobachten (interaktive Karte des Nordharzes hier):
- Eckertalsperre
- Eintrag auf Wikipedia
- Pegelstand des Niedersächsischen Landesbetriebs für Wasserwirtschaft,Küsten- und Naturschutz (NLWKN)
- Flussfolge: Ecker → Oker → Aller → Weser
- Granetalsperre
- Eintrag auf Wikipedia
- Pegelstand des NLWKN
- Flussfolge: Grane → Innerste → Leine → Aller → Weser
- Innerstetalsperre
- Eintrag auf Wikipedia
- Pegelstand des NLWKN
- Flussfolge: Innerste → Leine → Aller → Weser
- Odertalsperre
- Eintrag auf Wikipedia
- Pegelstand des NLWKN
- Flussfolge: Oder → Rhume → Leine → Aller → Weser
- Okertalsperre
- Eintrag auf Wikipedia
- Pegelstand des NLWKN
- Flussfolge: Oker → Aller → Weser
- Sösetalsperre
- Eintrag auf Wikipedia
- Pegelstand des NLWKN
- Flussfolge: Söse → Rhume → Leine → Aller → Weser
Die Grane-, Oker- und Innerstetalsperre bilden zusammen das "Nordharzverbundsystem" (Link öffnet PDF der Harzwasserwerke zum Neubewilligungsverfahren des Verbundes 2017), welches unter allen sechs Talsperren die Hauptverantwortung für die Trinkwasserversorgung aus dem Harz trägt. Zu diesem Zweck existiert eine wasserführende Verbindung zwischen der Oker- und der Granetalsperre, der Oker-Grane-Stollen, eine Pumpleitungsverbindung Innerste- zur Granetalsperre (knapp 50m Höhenunterschied) und der Radau-Stollen vom Fluss Radau zur Okertalsperre (und folglich auch zu Granetalsperre).
Zwar veröffentlichen der NLWKN und die Harzwasserwerke GmbH statistische und wasserwirtschaftliche Untersuchungen wie z.B. dieses sehr interessante Papier "Wasserwirtschaft im Harz 1941 - 2018" des Jahres 2018, auf den öffentlich zugänglichen Seiten sind bis auf derartige Kompendien und die täglichen Talsperren-Wasserstandsdaten jedoch kaum zeitnahe oder historische Zahlen zu finden.
Diese täglichen Wasserstandsdaten der Harzwasserwerke enthalten die Staustände inklusive des Niederschlags, Zuflusses, sowie der Unterwasserabgabe in Form einer PDF-Datei (Gesamtübersicht dort genannt). Die PDFs lud ich mir seit Herbst 2018 mehr oder minder regelmäßig runter, um die Assoziation jährliches Wetter im Verhältnis zum Stand der Talsperren (und damit im Verhältnis zur teilweisen Sicherstellung unserer Trinkwasserversorgung) selbst genauer beobachten zu können.
2. Auswertungen der Daten der Harzer Talsperren
2021 im Sommer begann ich dann, diese PDF-Daten in einer Datenbank zu speichern, und grafisch auszuwerten. Die Daten enthalten für jeder der sechs Talsperren die Werte
- Stand: Zeitpunkt der Erstellung der Daten, hoffentlich auch in etwa der der Messungen
- Niederschlag: in Millimetern (Liter pro Quadratmeter) zwischen Vortag 07:30 und dem Zeitpunkt der Gesamtmessung. Nur an der Talsperre gemessen, nicht im gesamten Einzugsgebiet
- Stauhöhe: aktueller Wasserstand in Metern über Normalnull
- Stauinhalt: aktueller Gesamtinhalt (oder entnehmbarer Inhalt?) in Millionen Kubikmetern
- Füllungsgrad: Inhalt relativ zum Maximalinhalt in Prozent
- Zufluss: insgesamt zufließendes Wasser in Kubikmetern pro Sekunde
- UW-Abgabe: Unterwasserabgabe, also steuerbarer Abfluss in den folgenden Ablauf (Fluss) in Kubikmetern pro Sekunde
Ausgehend von diesen Daten schrieb ich mir ein Skript (kleines Programm), das einzelne Grafikdateien vom zeitlichen Verlauf und Vergleich dieser Größen liefert. Sinn der verschiedenen grafischen Darstellungen ist der Versuch, durch unterschiedliche Blickwinkel auf die Daten mögliche Zusammenhänge zwischen den Werten erkennbar zu machen (Data-Mining im Kleinen, da nur geringfügige Datenmenge), die auf individuelle Eigenschaften der jeweiligen Talsperren oder der Region hinweisen könnten.
3. Aktuelle und jährliche absolute Stauinhalte
Die Stabilität der Trinkwasserversorgung hängt in erster Linie vom Gesamtstand der versorgenden Talsperren ab, daher zuerst die Visualisierung der aufsummierten absoluten Stauinhalte aller sechs Talsperren. Der maximal mögliche Inhalt beträgt 182 Millionen Kubikmeter. Die Entwicklungen in Jahresintervallen:
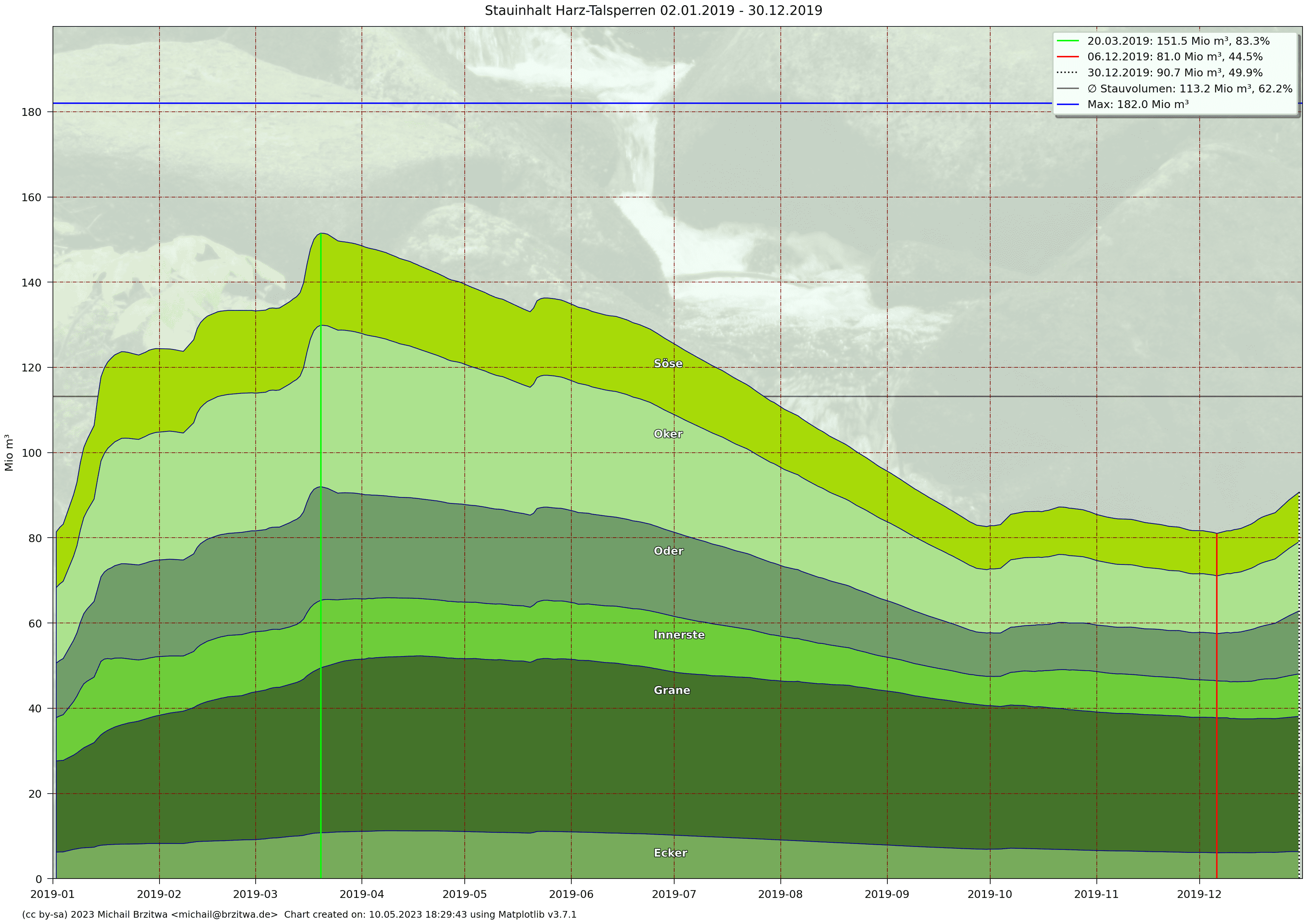
Stauinhalt Harzer Talsperren 2019
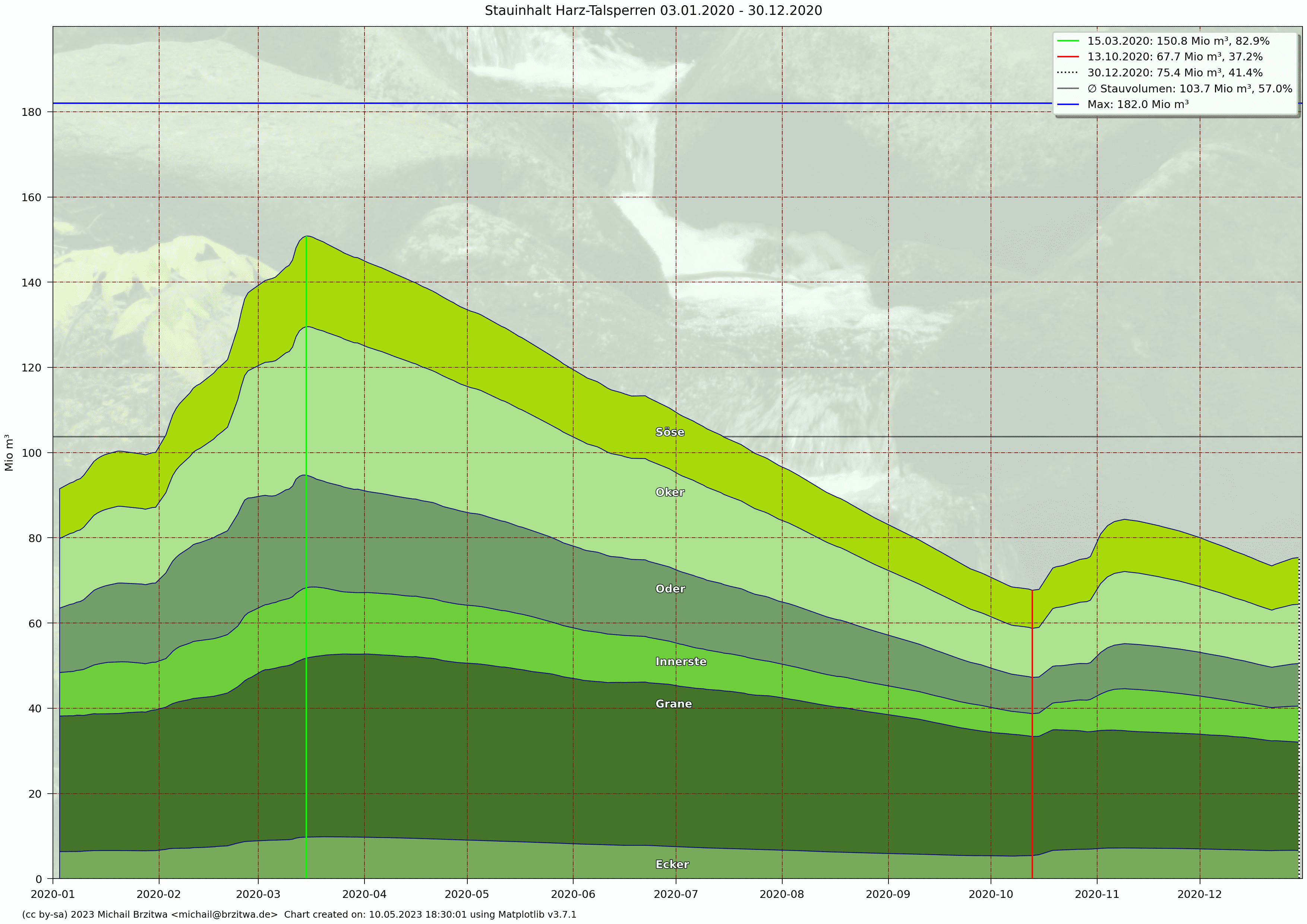
Stauinhalt Harzer Talsperren 2020
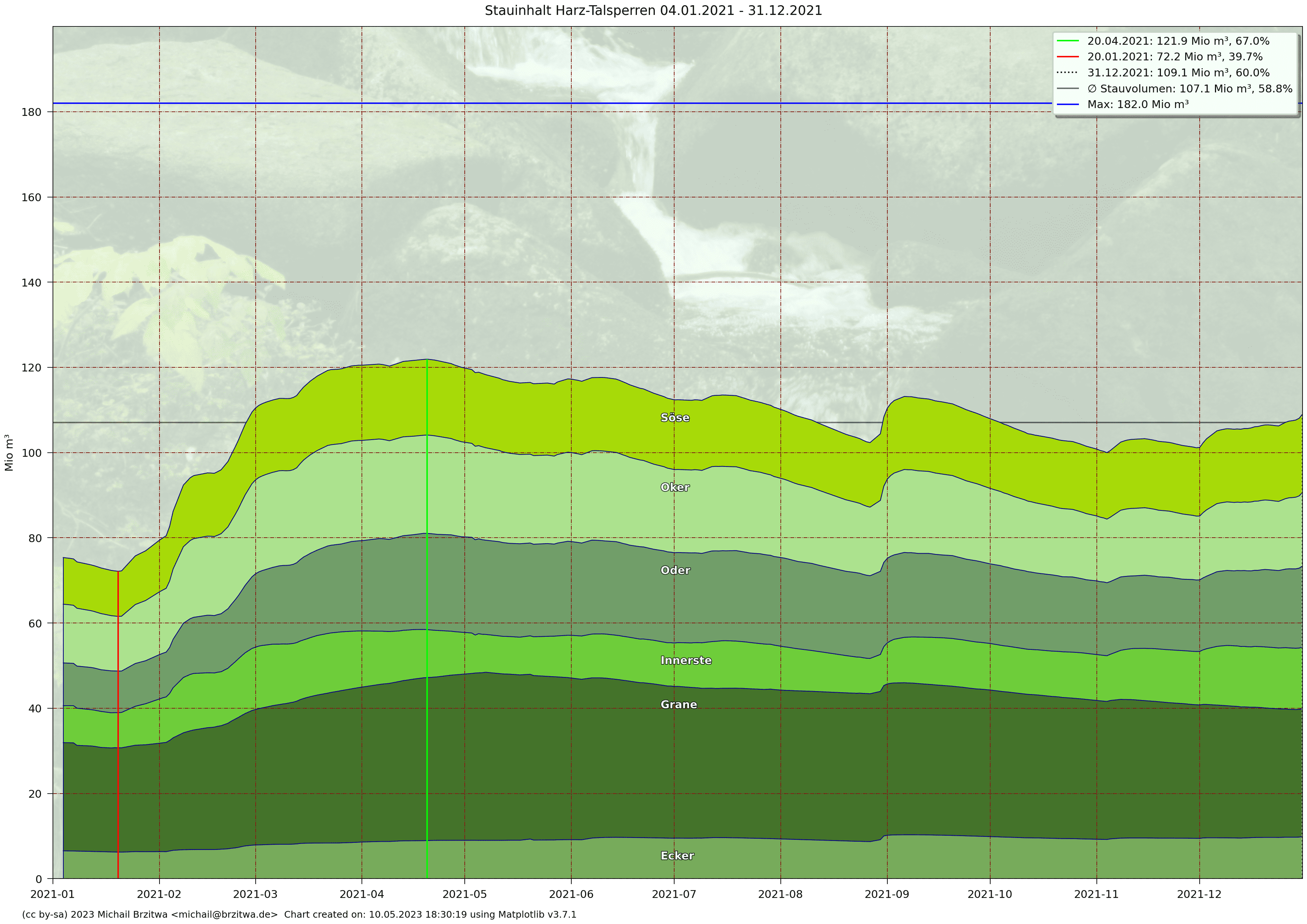
Stauinhalt Harzer Talsperren 2021
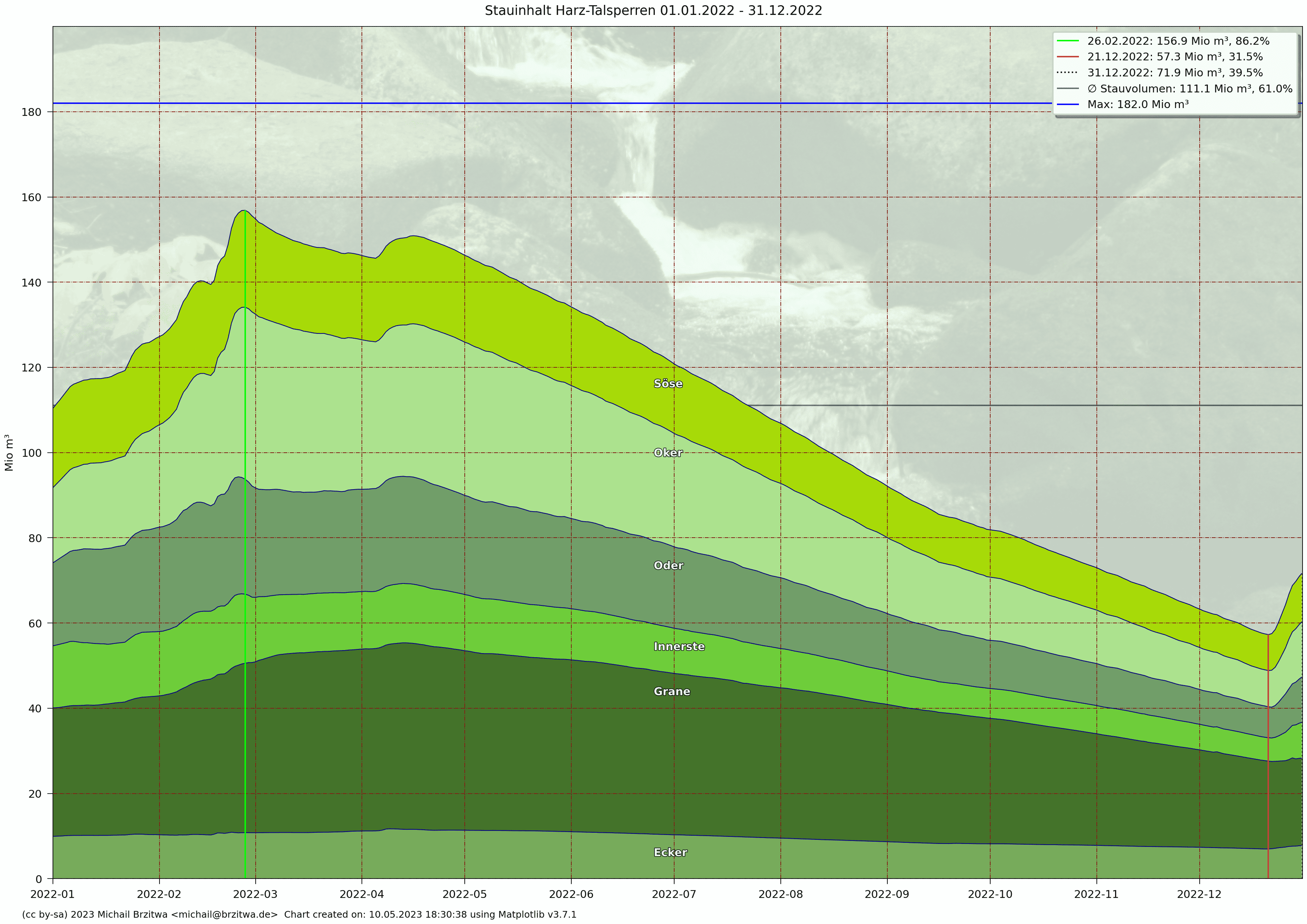
Stauinhalt Harzer Talsperren 2022
|
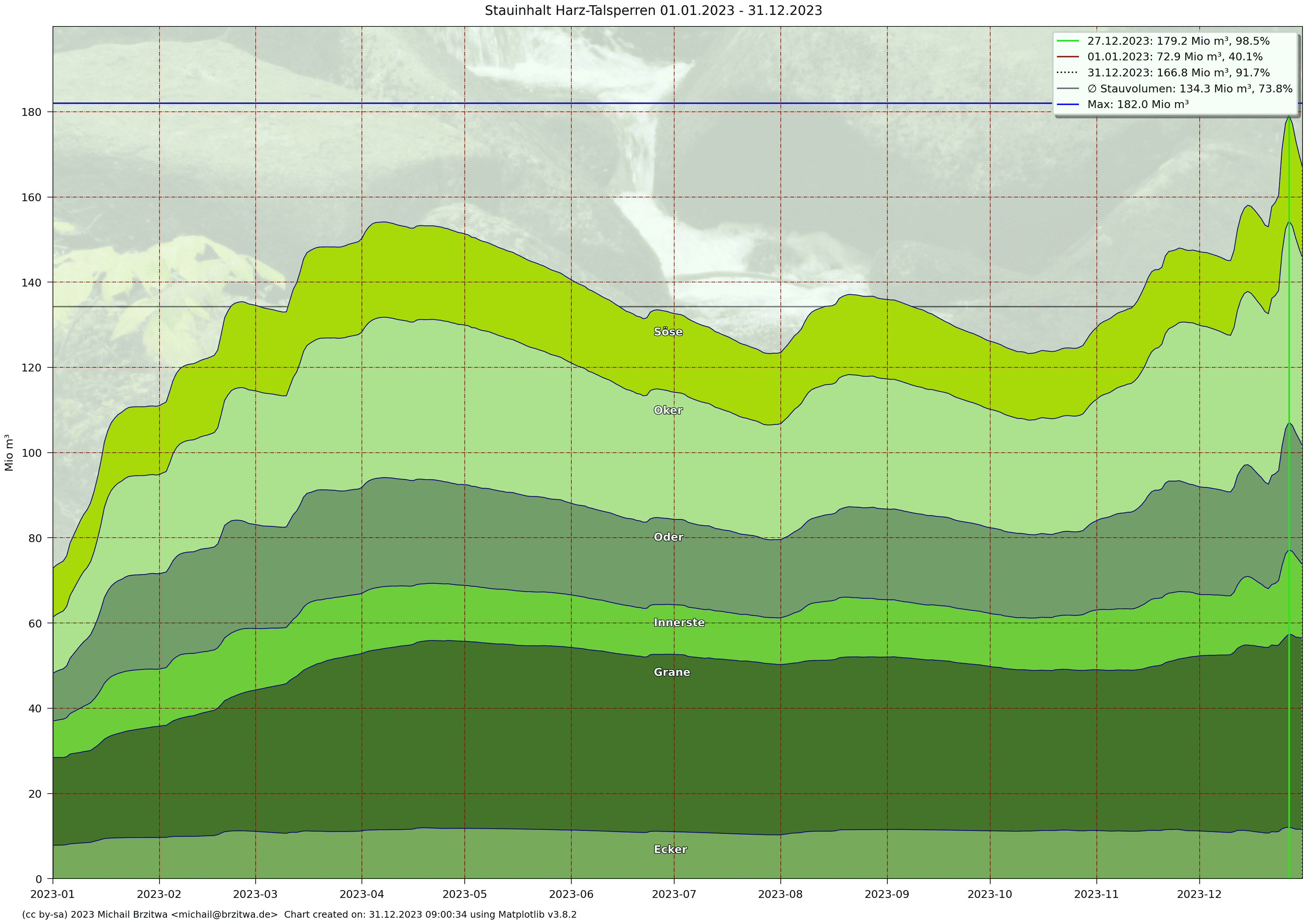
Stauinhalt Harzer Talsperren 2023
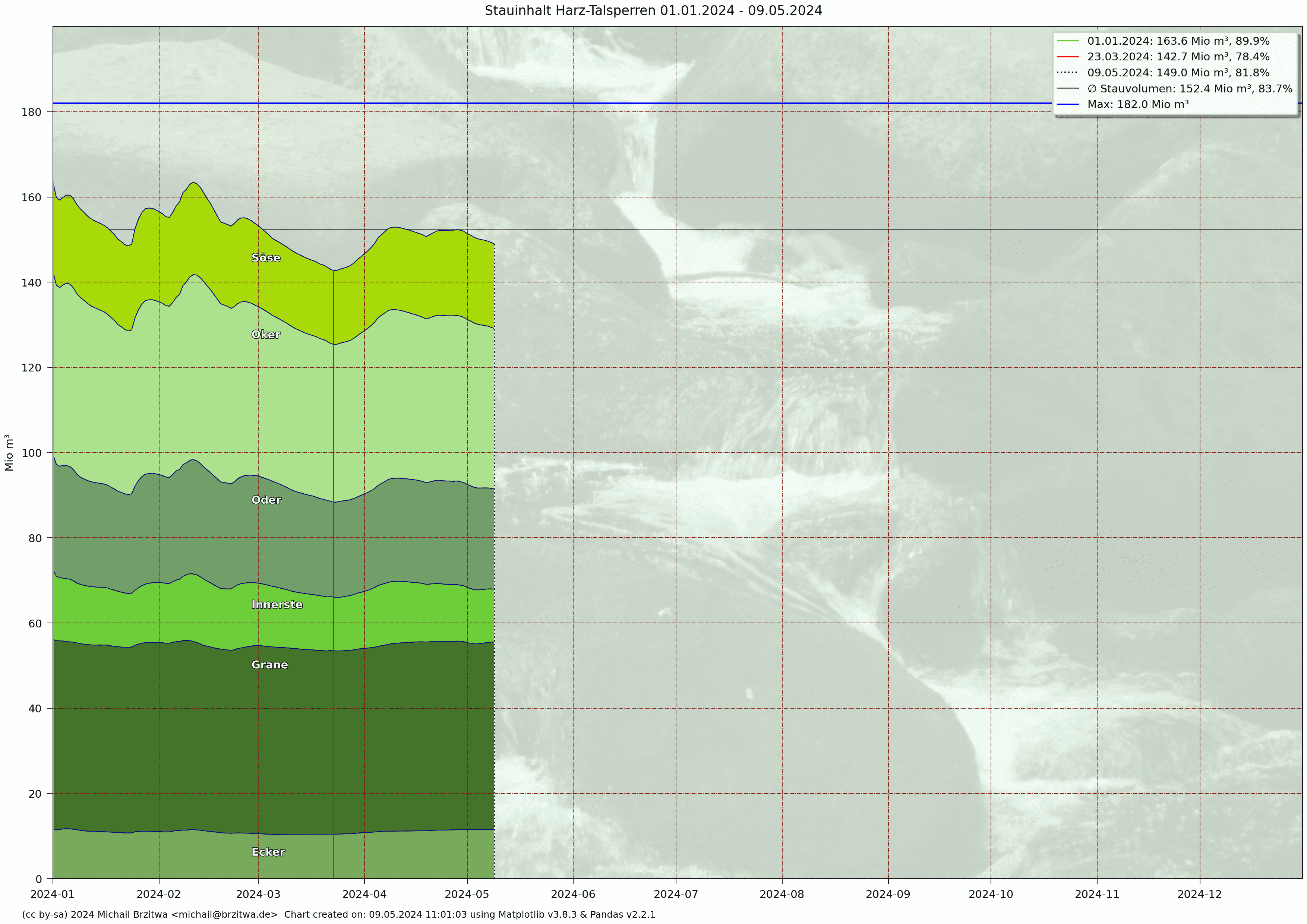
Stauinhalt Harzer Talsperren 2024

Stauinhalt Harzer Talsperren 2025
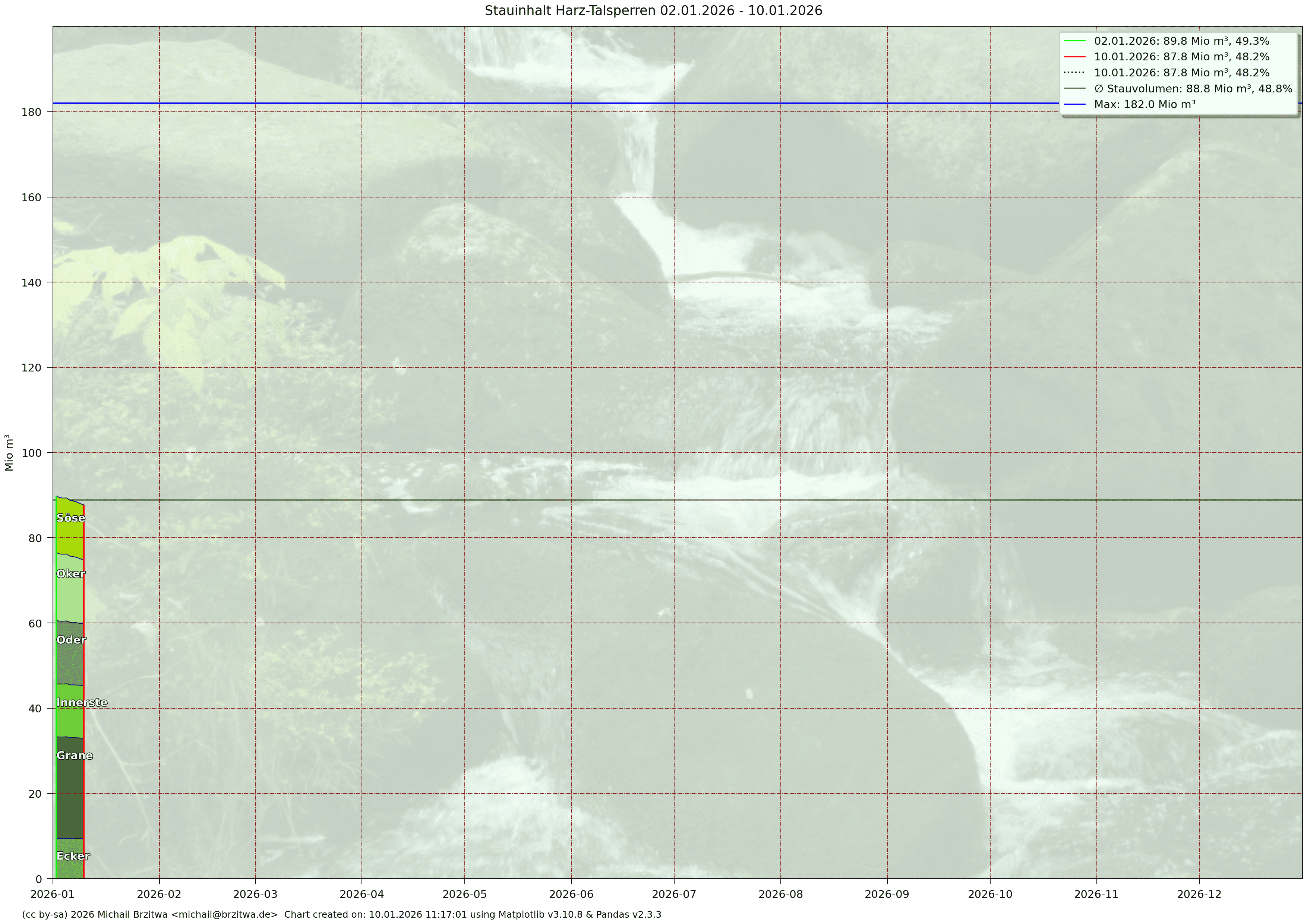
Stauinhalt Harzer Talsperren 2026
|
Man kann schön als zuflussreichste Zeit das erste Quartal zwischen Anfang Januar und Ende März identifizieren. In 2019 stieg in dieser Periode der Gesamtstand von etwas über 80 Mio m³ auf über 150 Mio m³, also fast eine Verdopplung des Stauvolumens. Ab Anfang/Mitte April fällt der Inhalt dann jahreszeitlich bedingt regelmäßig und stetig ab. Der durchschnittliche Stauinhalt aller Talsperren im Verbund betrug
- 94 Mio m³ in 2026 (52%) bisher
- 108 Mio m³ in 2025 (60%)
- 138 Mio m³ in 2024 (76%)
- 134 Mio m³ in 2023 (74%)
- 111 Mio m³ in 2022 (61%)
- 107 Mio m³ in 2021 (59%)
- 104 Mio m³ in 2020 (57%)
- 113 Mio m³ in 2019 (62%)
Ich sollte hier vielleicht noch schnell einschieben, dass meine Deutungen hauptsächlich auf Laienwissen beruhen, insbesondere auf Wikipedia-Einträge zu Stauseen und ähnlichen Quellen. Ich habe nie Wasserwirtschaft studiert, ich weiss nicht einmal, wie man das schreibt. Meine Interpretationen also bitte nicht überbewerten, die können auch ganz leicht ganz weit danebenliegen. Nichtsdestotrotz.
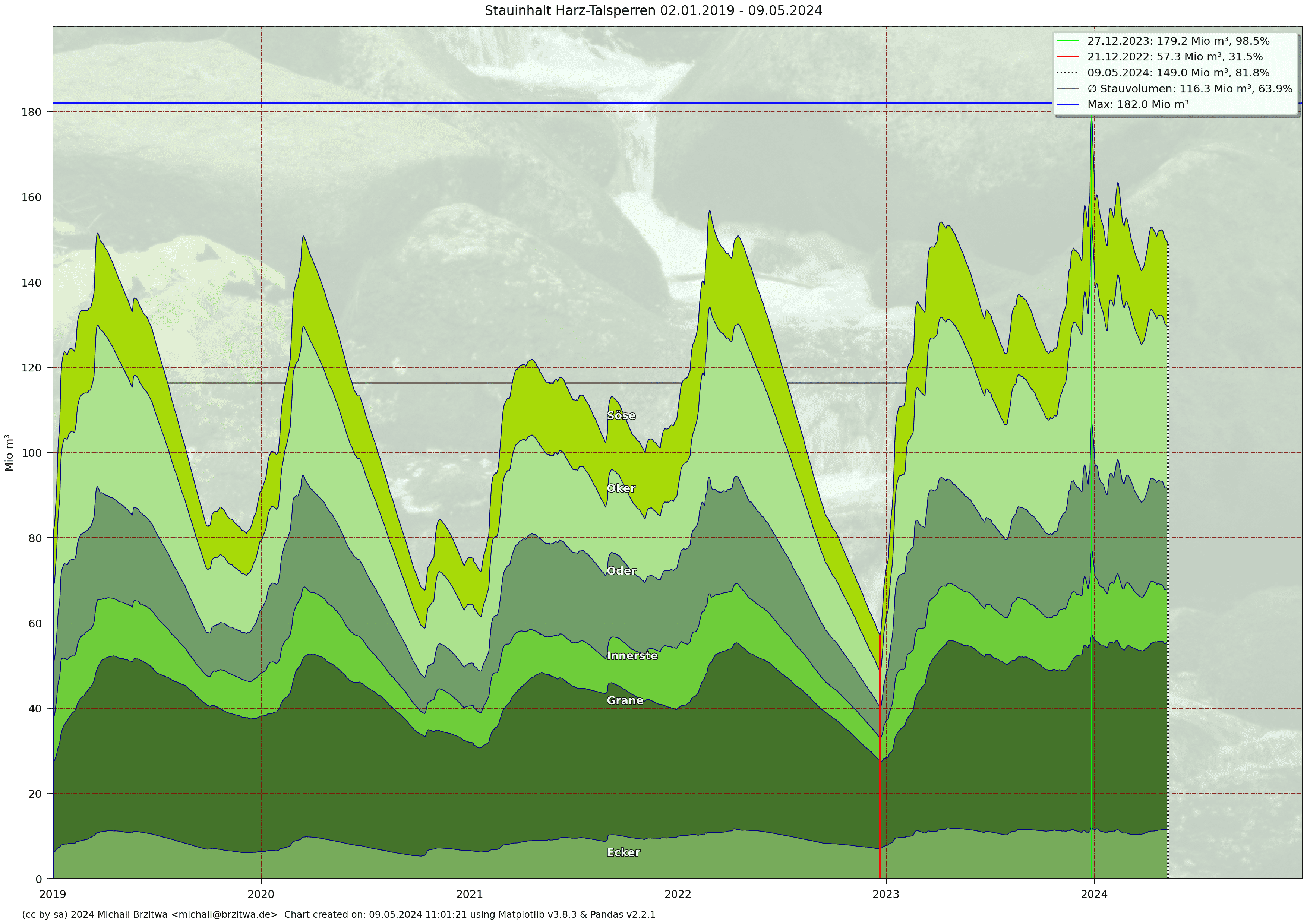
Stauinhalt Harzer Talsperren 2020 - 2026
|
Das Jahr 2021 zeigte eine geringere Dynamik als die beiden vorausgegangenen Jahre: ein geringerer Gesamtpegel, aber dafür aufgrund des regenreicheren Sommers ein höheren Stauinhalt im Herbst. In Zahlen: der maximale Stauinhalt aller Talsperren 2021 lag mit knapp über 120 Mio m³ weit unter den 150 Mio m³ in den beiden vorausgehenden Jahren. Andererseits aber nahm dieser Inhalt bis in den Herbst auf nur 100 Mio m³ ab gegenüber zum Teil weniger als 80 Mio m³ in 2018, 2019 und 2020.
2022 startete mit einem relativ hohem Pegel, resultierend aus einem vergleichsweise geringem Rückgang im Sommer und Herbst 2021. Zur Veranschaulichung die Gesamtpegelstände an den Jahreswechseln:
- 2025 auf 2026: 90,2 Mio m³
- 2024 auf 2025: 144,1 Mio m³
- 2023 auf 2024: 163,6 Mio m³
- 2022 auf 2023: 72,9 Mio m³
- 2021 auf 2022: 110.4 Mio m³
- 2020 auf 2021: 75,4 Mio m³
- 2019 auf 2020: 90,8 Mio m³
- 2018 auf 2019: 78,1 Mio m³
Der Sommer 2022 dann ab Mitte April zeichnete sich durch hohe Temperaturen (großflächig bis zu 39°C), Trockenheit und Dürre aus. Im September gab es zwar etwas Niederschlag, aber durch den vergleichsweise sehr warmen und regenarmen Oktober und November gab es trotzdem keine Pegelzunahme der Talsperren. Bis lange in dem Dezember hinein fehlten signifikante Regenmengen, erst in den letzten beiden Wochen des Jahres konnte wieder ein Nettozufluß der sechs Talsperren verzeichnet werden.
Das erste Quartal 2023 ähnelte in Niederschlag und Zufluß bisher dem Jahr 2019, auch Q2 und Q3 brachten einem normal feuchten Sommer hier im Norden. Es gab kaum Tage mit Temperaturen über 30°C, dafür aber immer wieder Phasen mittleren bis starken Niederschlags, resultierend in einem seit Anfang August wieder gleichbleibendem und teils auch ansteigendem Gesamtfüllstand.
Mitte November 2023 nun stieg der summierte Pegel aller sechs Talsperren auf über 140 Mio m³, worauf die Harzwasserwerke die Unterwasserabgaben (Abflüsse) der Talsperren Innerste, Oder und Söse teils stark anhoben, die der Söse zum Beispiel auf den höchsten Wert der letzten fünf Jahre: 6 m³/s, 6000 Liter pro Sekunde, also ca. fünfhundertausend Kubikmeter pro Tag.
Im Dezember 2023 stieg der Summenpegel sogar auf knapp 180 Mio m³, übertraf mit 179,2 Mio m³ am 27. Dezember das bisherige Maximum am 7. April, und stellt damit den höchsten Staustand seit mindestens 5 Jahren dar.
Die Oker- und Innerstetalsperre meldeten in der Nacht vom 25.12.2023 auf den 26.12.2023 Vollstau, und es kam dort in Folge zur sogenannten Hochwasserentlastung. Beide Talsperren liessen dann bis etwa Mitte Januar verstärkt Stauwasser ab.
In der Nacht auf den 29.12.2023 fielen die Füllgrade aller sechs Talsperren wieder unter 100%, allerdings blieben die Wasserabgaben noch etwa zwei Wochen relativ hoch. Selbst die Granetalsperre, eigentlich hauptsächlich als Trinkwasserreservoir konzipiertes Volumen, ließ etwas mehr Wasser als sonst ab, da sie in einer Vollstau-Situation der Okertalsperre diese durch den Oker-Grane-Stollen entlasten kann.
Das Weihnachtshochwasser 2023 dauerte bis etwa Ende Januar 2024, allerdings blieben noch über mehrere Wochen bis teilweise in den März hinein viele Flächen überflutet, da ein Versickern aufgrund des oft hohen Sättigungsgrads des Bodens viel Zeit brauchte.
Das gesamte Jahr 2024 ähnelte 2021 insoweit, als dass relativ hohe Niederschläge auf eher gemäßigte Sommer- und Herbsttemperaturen trafen, resultierend in einer geringeren Spannbreite der Füllstände: Abstand Minimum zum Maximum 47,6 Mio m³, im Vergleich dazu das trockene Jahr 2022: 99,6 Mio m³.
Dieser Unterschied muß nicht notwendig allein auf natürliche Umstände wie Niederschlag, Verbrauch, Oberflächenabfluß und Verdunstung, sondern kann vielleicht auch auf Änderungen der Unterwasserabgaben seitens der Harzwasserwerke zurückgeführt werden. Wie aus den Einzeldarstellungen der Talsperren entnommen werden kann, scheinen die HWW insbesondere die Ecker- und Grantalsperrenabflüsse anders als in den Vorjahren zu handhaben.
Das Jahr 2025 war wiederum gekennzeichnet durch im Schnitt zu geringem Niederschlag und somit auch mit zu geringem Zufluß. Zwar waren Sommer und Frühherbst des Jahres nicht so heiss wie etwa 2022, das durchschnittliche Stauvolumen aller sechs Sperren fiel geringer als 2022 aus (108 Mio m³ vs. 111 Mio m³). Bis auf etwas mehr Regen im August war die zweite Jahreshälfte niederschlagsarm, was man am geringen Stand am Jahreswechsel zu 2026 (49,6% des Gesamtstauvolumens von 180 Mio m³) sehen kann.
Im Januar und Februar 2026 fiel reichlich Schnee in Niedersachsen und somit auch im Harz. Bis etwa Mitte, Ende Februar blieb es auch relativ kalt, weswegen die Schneeschmelze im Harz erst dann durch kräftigen Regen bei für einen Februar gemäßgten Temperaturen einsetzte.
| Jahr | Minimum | Durchschnitt | Maximum | Abweichung vom Durchschnitt |
|---|---|---|---|---|
| 2026 | 86,5 | 93,9 | 117,5 | -7,4 ... 26,3 |
| 2025 | 73,7 | 108,1 | 155,0 | -34,4 ... 46,9 |
| 2024 | 116,0 | 138,2 | 163,6 | -22,2 ... 25,4 |
| 2023 | 72,9 | 134,3 | 179,2 | -61,4 ... 44,9 |
| 2022 | 57,3 | 111,1 | 156,9 | -53,8 ... 45,8 |
| 2021 | 72,2 | 107,1 | 121,9 | -34,9 ... 14,8 |
| 2020 | 67,7 | 103,7 | 150,8 | -36,0 ... 47,1 |
| 2019 | 81,0 | 113,2 | 151,5 | -32,2 ... 38,3 |
Aus der Differenz "Höchststand Januar-April - Anfangspegel Januar" ergibt sich dann ein quantitatives Maß der Nordharz-Niederschläge im ersten Jahresdrittel. Wegen des Hochwasserstands noch am Jahreswechsel 2023/2024 ist diese Differenz im Jahr 2024 natürlich 0:
- 2025: 11,9 Mio m³
- 2024: 0,0 Mio m³
- 2023: 81,2 Mio m³
- 2022: 46,5 Mio m³
- 2021: 46,6 Mio m³
- 2020: 59,3 Mio m³
- 2019: 70,1 Mio m³
Die auf den Zeitraum 2019 - 2022 bezogene, überdurchschnittliche Regenmenge des ersten Drittels 2023 ist offenkundig, während die sehr geringe Differenz beider Pegel im Jahr 2025 auf unterdurchschnittlichen Zufluß, und damit auch unterdurchschnittlichen Niederschlag im ersten Drittel 2025 hindeutet.
Wie erwähnt bilden die Stauseen Grane, Innerste und Oker als Nordharzverbundsystem die Eckpfeiler der Trinkwasserversorgung der Harzer Talsperren. Diese drei verfügen über einen Gesamtstauinhalt von 112,5 Mio m³, ein Gesamteinzugsgebiet von 204 km² und, soweit ich das überblicke, eine wasserrechtliche Bewilligung für die Entnahme von knapp 85 Mio m³ Trinkwasser pro Jahr. Aus diesem Grund hier der aufsummierte Inhalt dieser drei Talsperren nochmal gesondert:
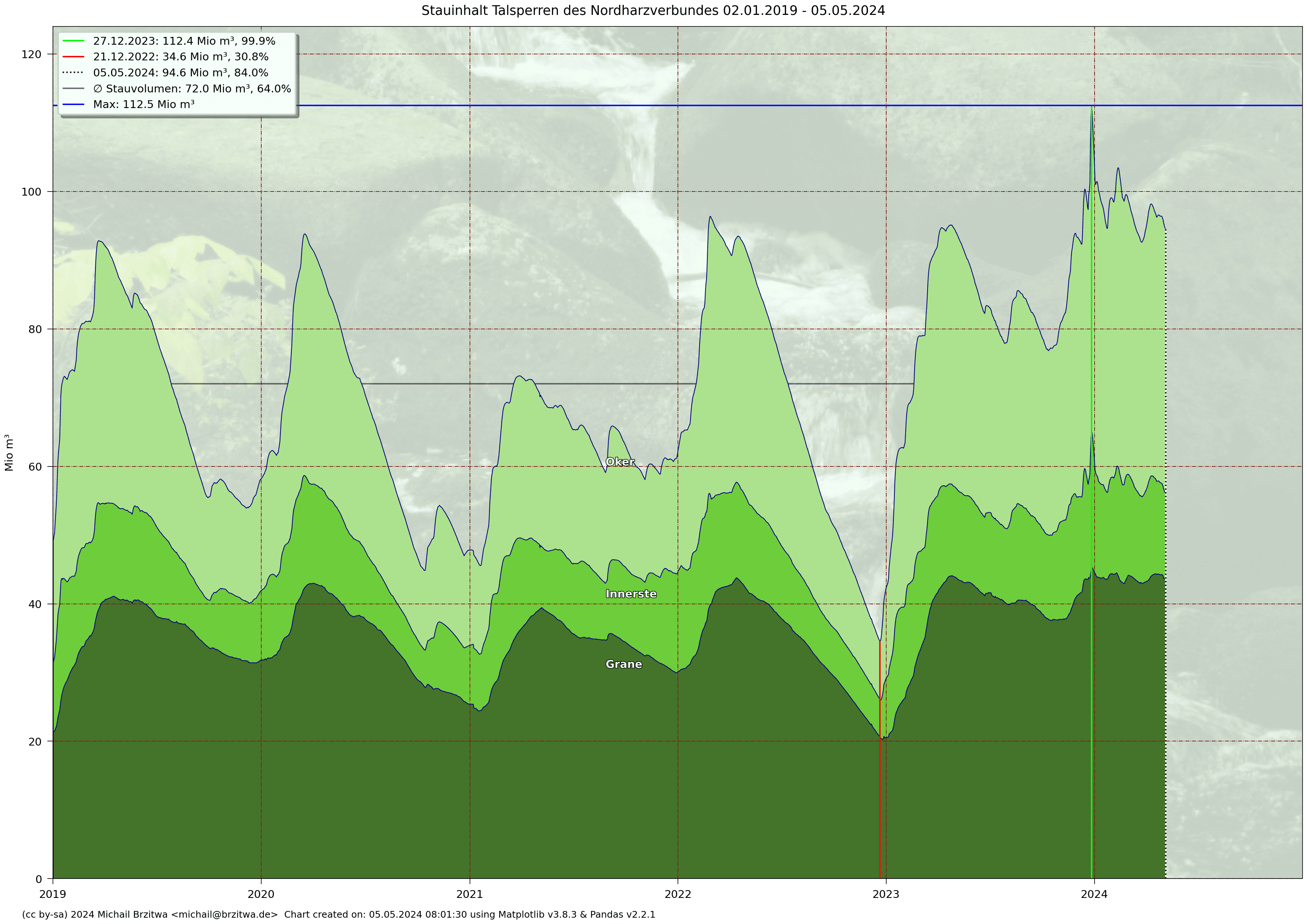
Stauinhalt Talsperren Nordharzverbundsystem 2019 - 2025
|
Der trinkwasserverwertbare Inhalt dieser drei Talsperren erreichte im Dezember 2023 nun seit über 5 Jahren zum ersten Mal die 110 Mio m³ Grenze.
Die Wahrscheinlichkeit längerer Trocken- oder sogar Dürre-Perioden steigt durch den Klimawandel offenbar, und erfordert dementsprechend mehr Rückhaltevolumen. Zwar scheinen schon seit Jahren Planungen für neue Speicherkapazitäten im Gang zu sein, siehe zum Beispiel den Bericht der "Zeitung für kommunale Wirtschaft" vom März 2021 über Planungen zusätzlicher Stauvolumen von bis zu 90 Mio m³, deren Realisierung wird jedoch noch lange Zeit benötigen, während Reaktionen auf geänderte klimatische Bedingungen zeitnah und kurzfristig erforderlich sind, um den Anteil des Harzwassers für die Trinkwasserversorgung Niedersachsens zu garantieren, stabilisieren oder sogar zu erhöhen.
Als mittelfristige Lösung wurde im März 2023 nun im Rahmen dieser Planungen eine mögliche Erweiterung (Aufhöhung) der Granetalsperre um 5 bis 12 Meter Stauzielhöhe, also ganz grob etwa um die Hälfte des aktuellen Stauvolumens von 46,4 Mio m³ vorgestellt. In diesem Bericht wird als möglicher Standort eines zusätzlichen Stauvolumens ein Stausee oberhalb der aktuellen Innerstetalsperre erwähnt.
Für einen direkten tagesweisen Vergleich aller Jahres-Pegelstände kann eine übereinandergelegte Darstellung hilfreich sein:
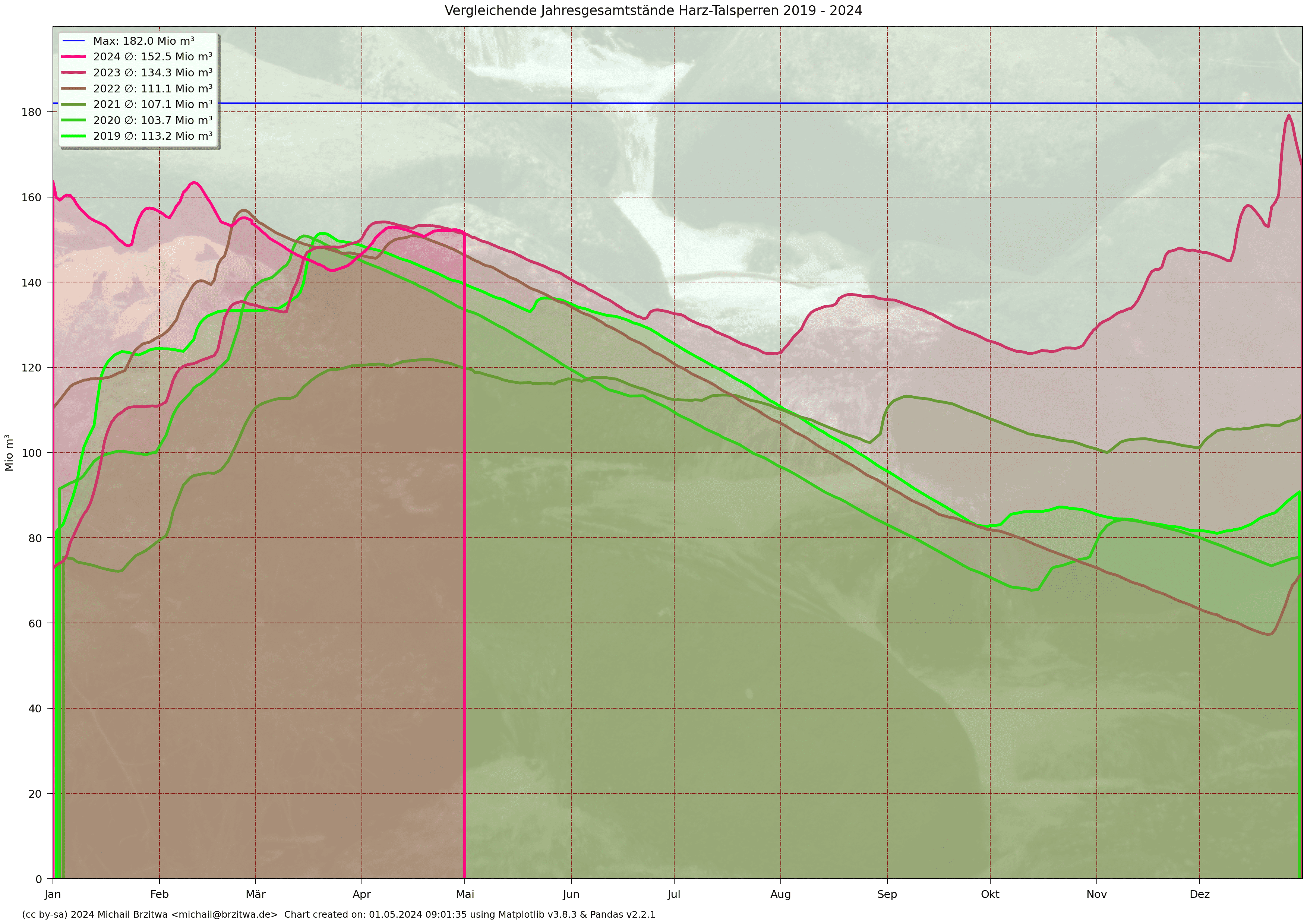
Vergleichende Jahresgesamtstände Harz-Talsperren 2022 - 2026
|
Der Pegelabfall aller sechs Talsperren in den Monaten Mai bis etwa Ende September beträgt grob über den Daumen relativ konstant 0.5 Mio m³ pro Tag. Bis auf die wettertechnisch gemäßigten Jahre 2021 und 2023 lässt sich diese Rate an allen Jahreskurven ablesen.
Dass der Pegel in 2022 trotz überdurchschnittlicher Dürreperiode vergleichweise eher moderat abnahm, hatte meines Erachtens zwei Gründe: der schon erwähnte hohe Jahresendpegel des feuchten und recht kühlen Jahres 2021 (ca. 30 Mio m³ mehr als 2018 auf 2019), und Anfang/Mitte April noch signifikanter Niederschlag (ca. 5 Mio m³).
Der Gesamtstand aller sechs Talsperren in 2022 unterschritt sogar den des Trockenjahres 2018. Aus der Warte der Harzer Talsperren war 2022 das trockenste Jahr seit inklusive 2018.
Das erste Quartal 2023 war sehr regenreich: das gesamte Stauvolumen aller sechs Harzer Talsperren wuchs von 72,9 Mio m³ Anfang Januar bis 154,1 Mio m³ Anfang April an. Über etwas mehr als drei Monate also ein Zufluss von 81,2 Mio m³ Regenwasser, fast 10 Mio m³ mehr als der gesamte Inhalt der Talsperren Anfang Januar.
Das entspricht knapp dem doppelten Inhalt des Steinhuder Meers, einem Würfel Wasser mit 433 Metern Kantenlänge, ca. 400000 Badewannen zu je 200 Litern, oder dem gesamten Jahreswasserverbrauch (~46,5 m³ pro Person) von etwa 1,7 Millionen Menschen, also etwa einem Fünftel der Einwohner Niedersachsens.
Das dritte Quartal 2023 brachte nochmals erheblichen Niederschlag im norddeutschen Raum, inklusive einem Netto-Volumenanstieg Anfang August aller sechs Talsperren von fast 14 Mio m³. Q4 2023 zeigte sich wiederum äußerst niederschlagsreich, insbesondere regnete es ab Ende Oktober fast täglich.
In den ersten Wochen 2024 schienen die Harzwasserwerke die Füllstände bzw. Unterwasserabgaben dynamischer als in den Vorjahren zu regeln, so betrug z.B. die Unterwasserabgabe der Granetalsperre in den ersten beiden Monaten der Jahre 2019 bis 2023 immer etwa 0,1 m³/s, in 2024 dagegen zwischen 0,2 und 2,0 m³/s, also zwischen der doppelten und zehnfachen Menge der Vorjahre. Strategie der Harzwasserwerke bleibt offenkundig der Balanceakt zwischen dem Vorhalt ausreichendem Stauvolumens zur Abfederung von Hochwassersituationen und dem Rückhalt genügend Wassers zur Trinkwasserversorgung und ggfs. Niedrigwasseraufhöhung.
Der Stand aller sechs Talsperren zum Ende des ersten Quartals 2024 von knapp 150 Mio m³ entsprach ungefähr dem Durchschnitt der letzten vier Jahre. Das zweite Quartal 2024 verlief mengenmäßig gesehen positiv, der summierte Stand zur Mitte des Jahres war der höchste seit mindestens 2019. Während im Süden Deutschlands Starkregenereignisse zu signifikanten Hochwassersituationen führten, fiel hier im Norden zwar einiger Niederschlag, aber nicht soviel, dass es zu Hochwässern reichte. Q3 2024 verlief ebenfalls gemäßigt, keine anhaltenden Hitzeperioden, dafür wiederum mehrere ergiebige Regentage, in Summe eine vergleichsweise eher leichte Abnahme der Staustände. Im letzten Vierteljahr 2024 setzten erwähnenswerte Regenmengen Mitte Oktober und dann durchgehend ab Mitte November ein, resultierend in einem, vom Hochwasserjahr 2023 abgesehen, höchsten Dezemberstand aller sechs Talsperren von über 140 Mio m³.
Diesem hohen Stand zum Jahreswechsel 2024/2025 war es zu verdanken, dass die summierten Pegelstände des ziemlich niederschlagsarmen Jahres 2025 nicht unter 40% sanken. Zwischen Februar und Mitte Oktober war kaum relevanter Zufluß zu verzeichnen, erst ab Ende Oktober stiegen die Wasserstände wieder etwas an.
Diesselbe vergleichende Darstellung der summierten Pegel des Nordharzverbundsystems Grane, Innerste und Oker:
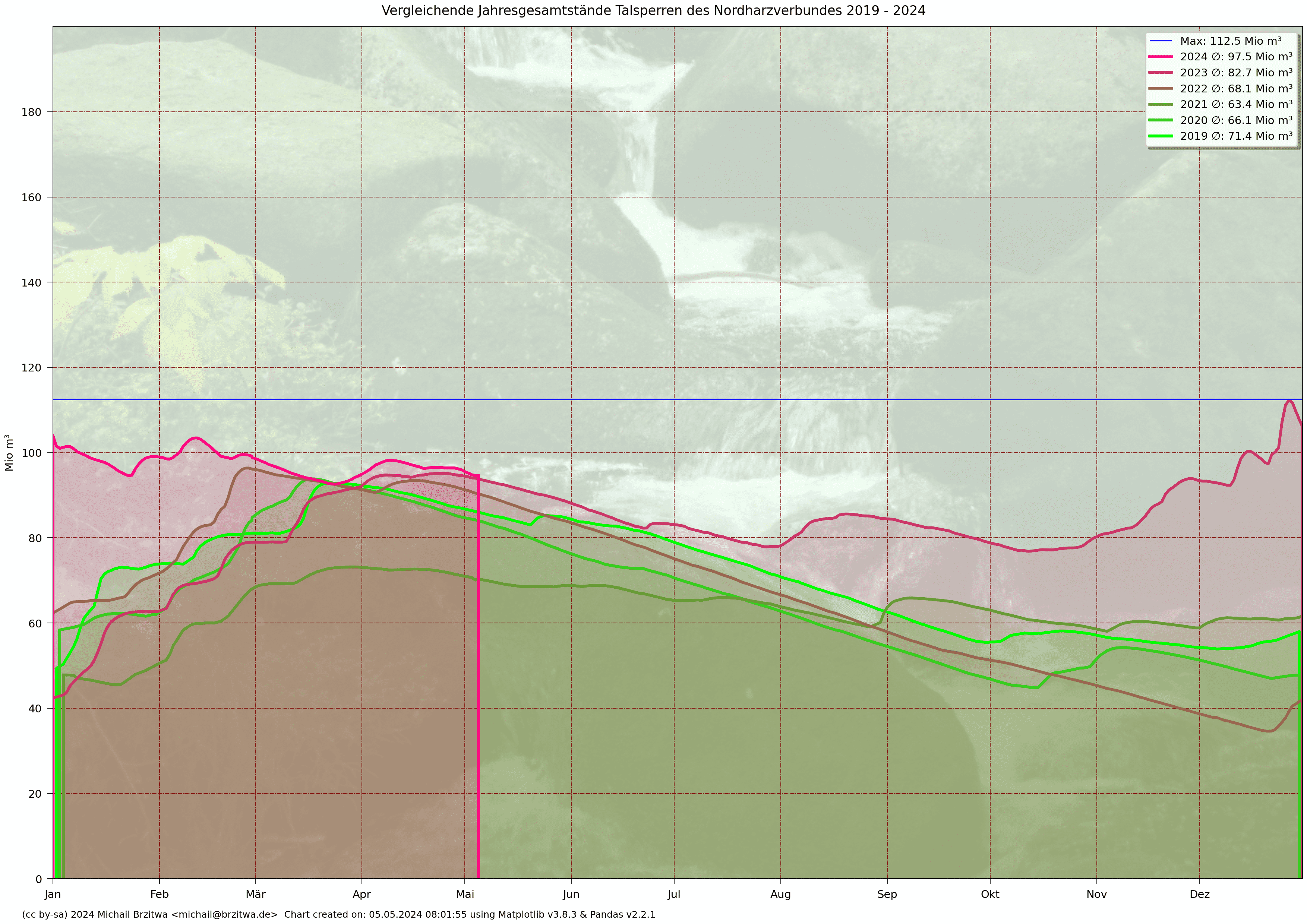
Vergleichende Jahresgesamtstände Talsperren Nordharzverbundsystem 2021 - 2025
|
Was ganz anderes: das Foto im Hintergrund obiger Charts

|
habe ich 2010 vom Bach "Schwarzes Schluftwasser" am Eckerlochstieg kurz oberhalb von Schierke gemacht. Den Aufstieg von Schierke durch den Eckerlochstieg hoch zum Brocken kann ich nur jedem empfehlen, den auch steilere und steinige Aufstiege nicht abschrecken können. Gutes Schuhwerk und ein bischen Lunge vorausgesetzt stellt dieser Weg zum Brocken einen der meiner Meinung nach schönsten Aufstiege zum Brocken hoch dar.
Beginn in Schierke bei Höhenmeter ca. 660, dann etwa 3,7km und 350 Höhenmeter hoch zur Brockenstraße, danach auf der Straße weitere 1,4km und 120Hm hoch zum Brocken. Durchschnittliche Steigung im Stieg um die 10%, Maximum irgendwo zwischen 30 und 45%, in den Bereichen teils mit Handläufen. Wir sind da auch mehrmals gut im Neuschnee hoch, allerdings empfehle ich einen Abstieg, also den Rückweg runter nach Schierke, bei Eis, Nassschnee oder Starkregen nur dann, wenn man vorher mit seiner Krankenkasse die zukünftige Pflegestufe erfolgreich aushandeln konnte. Granit kann schweineglatt sein.
Wem der Hin- oder Rückweg zu Fuß nicht so liegt, kann immer noch mit der Brockenbahn der Harzer Schmalspurbahnen (HSB) ab Wernigerode, Drei Annen Hohne oder Schierke hochfahren, immer eine schöne Sache. Hier eine kurzes Video unserer Fahrt zum Brocken am 13.02.2024:
4. Aktuelle und jährliche prozentuale Stauinhalte
Eine weitere Sicht auf die Stauseen-Daten ist der direkte Vergleich der prozentualen Stauinhalte, des relativen Füllungsgrades aller Talsperren inklusive dessen Minimum, Maximum, Durchschnitt, Median und Standardabweichung:
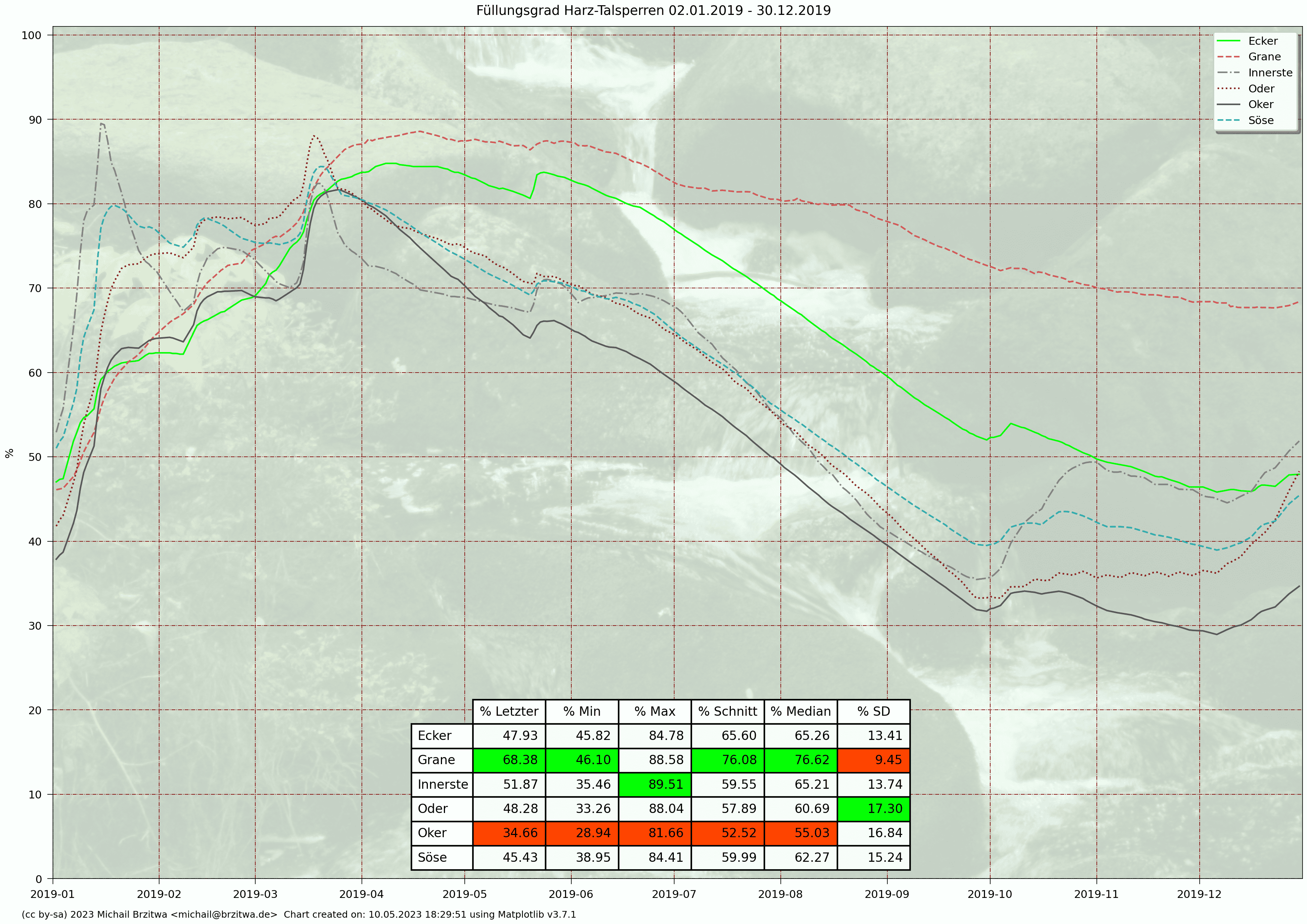
Relative Stauinhalte Harzer Talsperren 2019
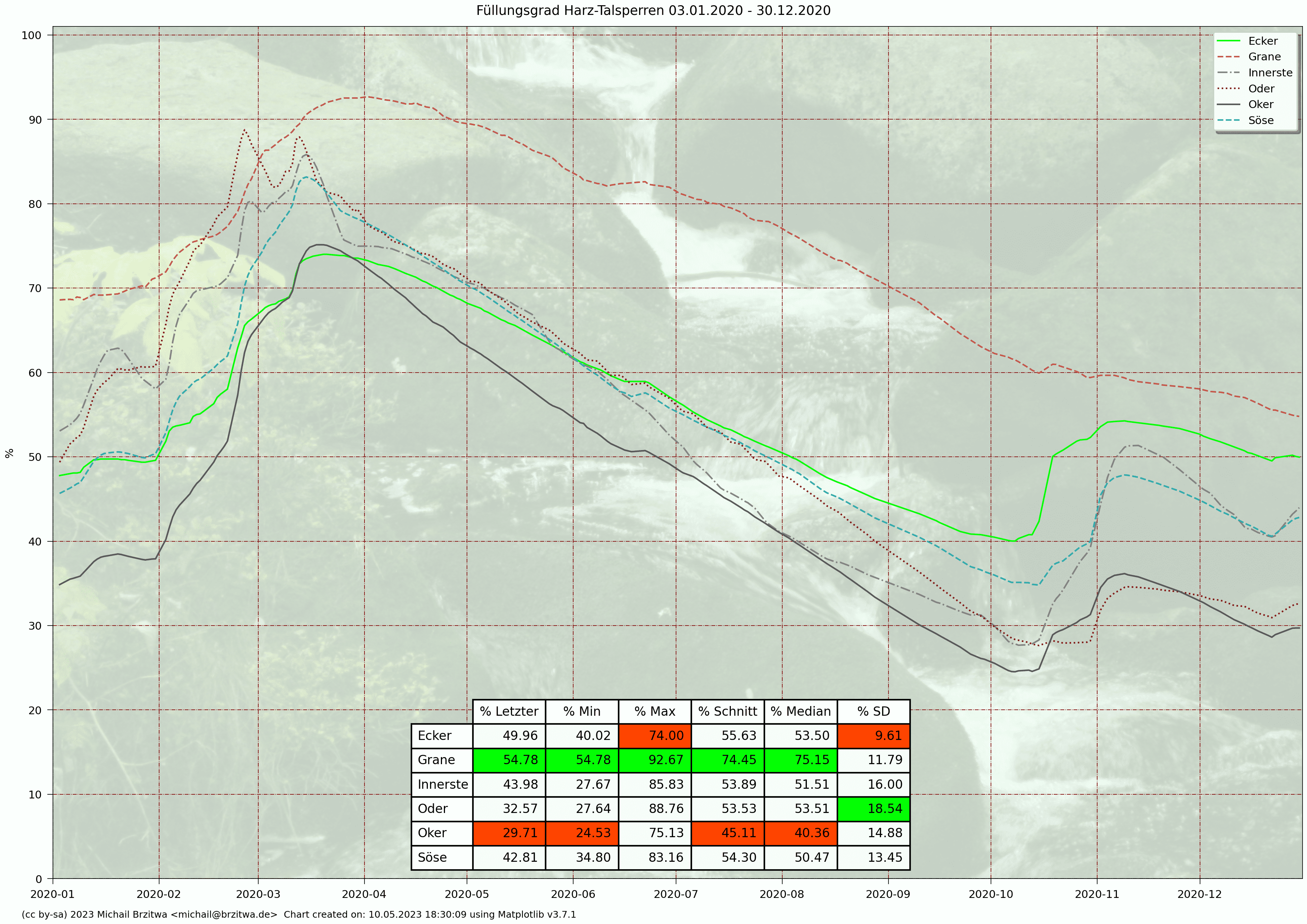
Relative Stauinhalte Harzer Talsperren 2020
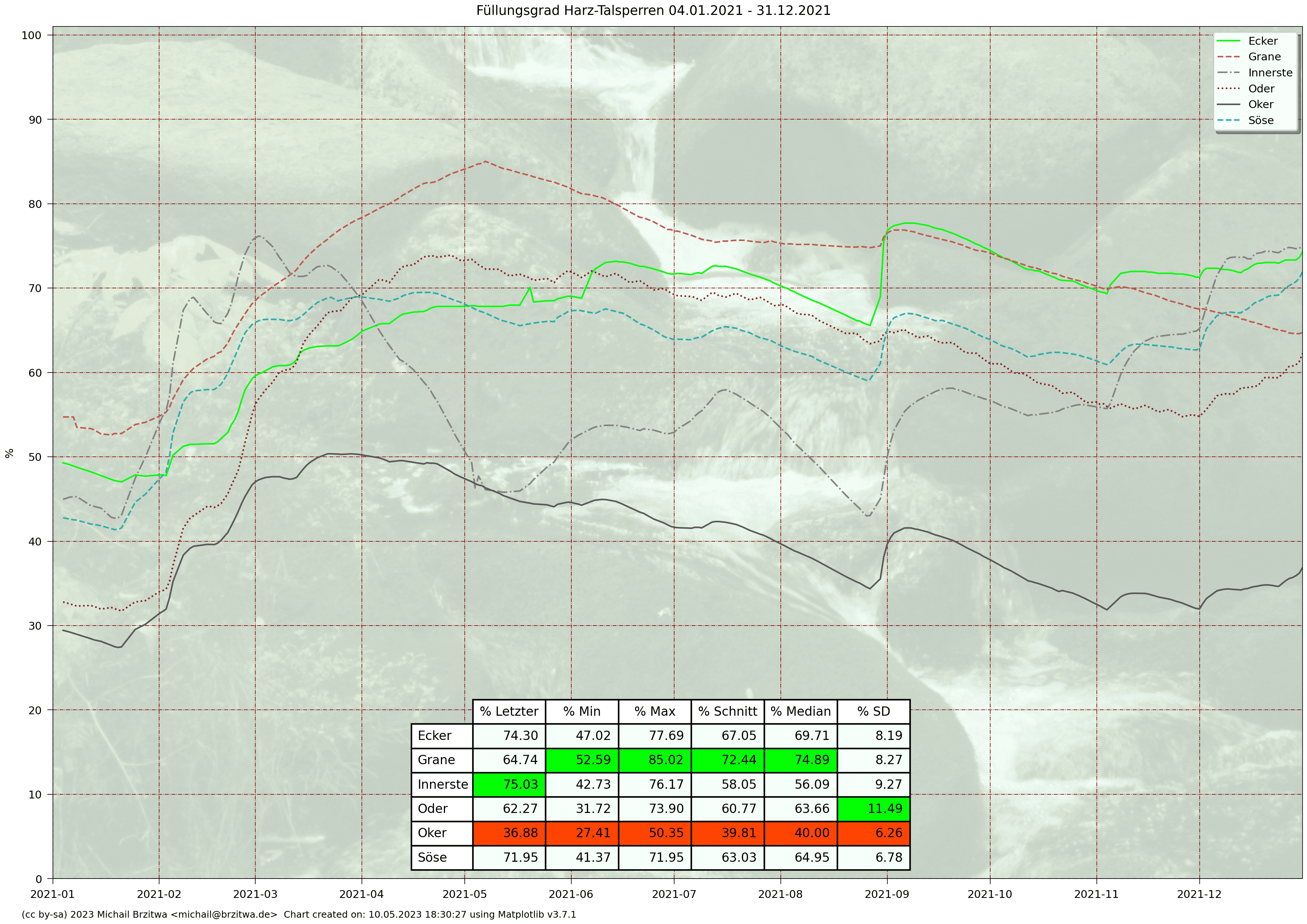
Relative Stauinhalte Harzer Talsperren 2021
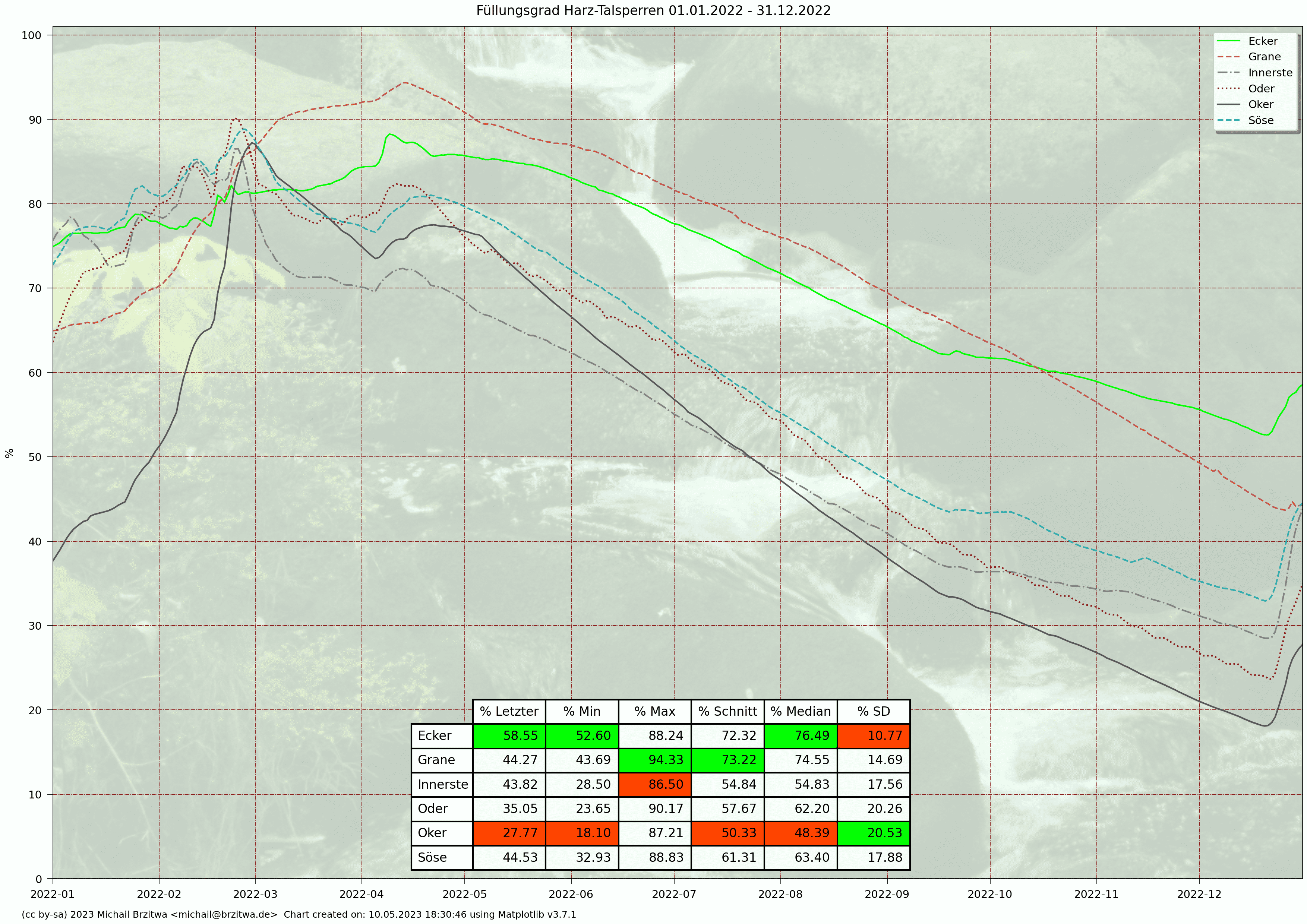
Relative Stauinhalte Harzer Talsperren 2022
|
Die geringsten Varianzen des Stauinhalts sind bei der Grane- und Eckertalsperre aufzufinden, wobei die Granetalsperre etwa das 3,5-fache Stauvolumen der Eckertalsperre besitzt.
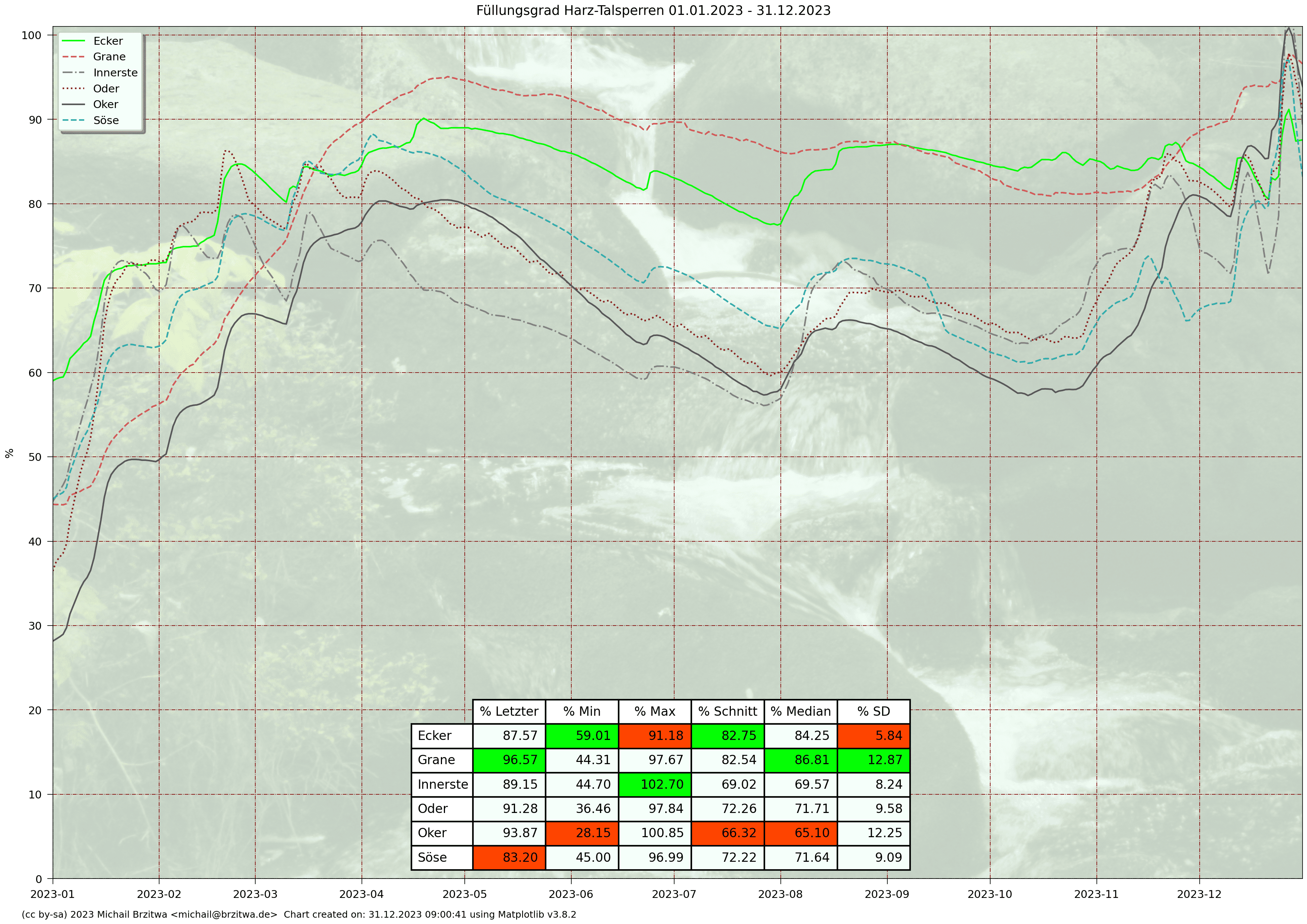
Relative Stauinhalte Harzer Talsperren 2023
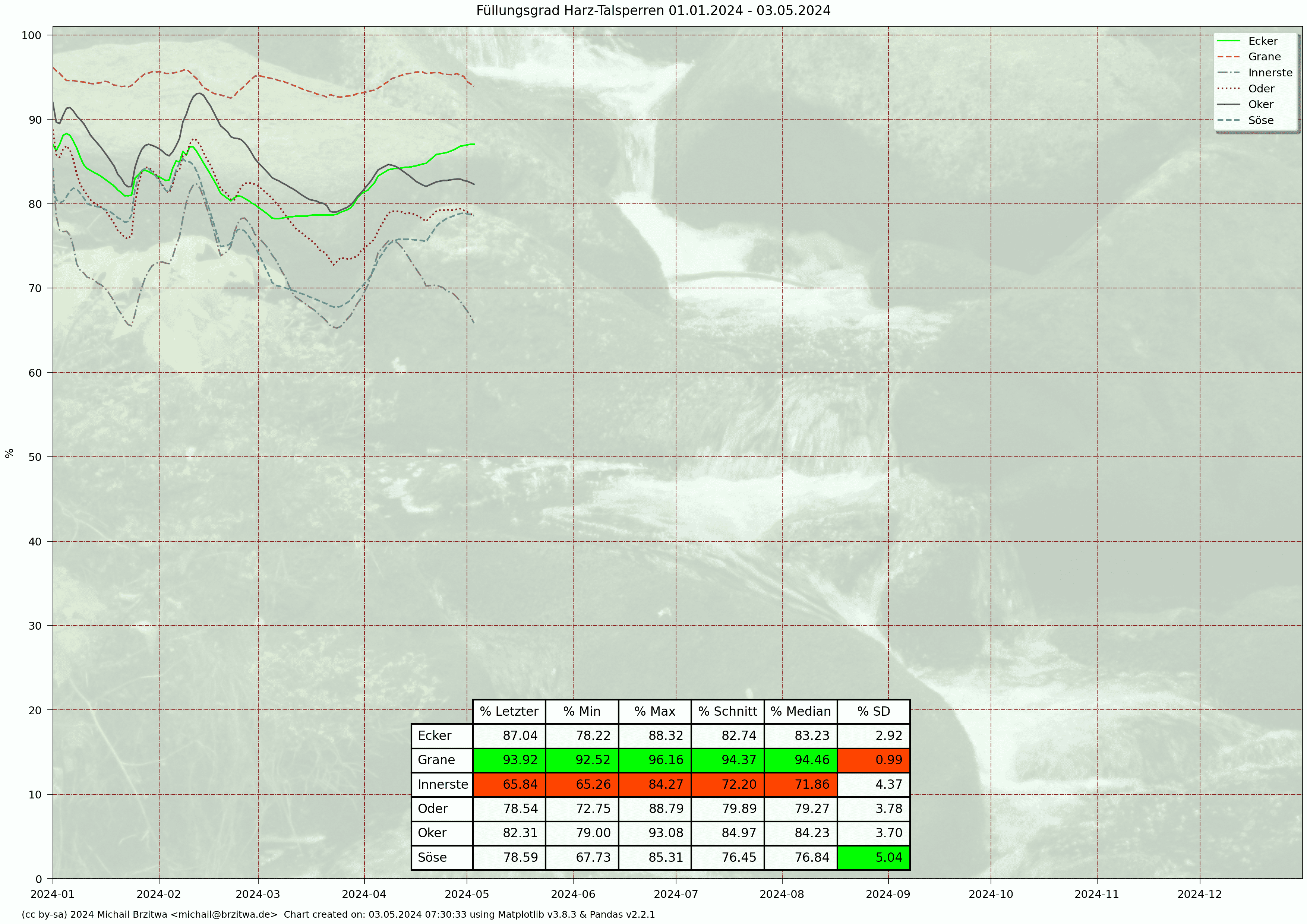
Relative Stauinhalte Harzer Talsperren 2024

Relative Stauinhalte Harzer Talsperren 2025
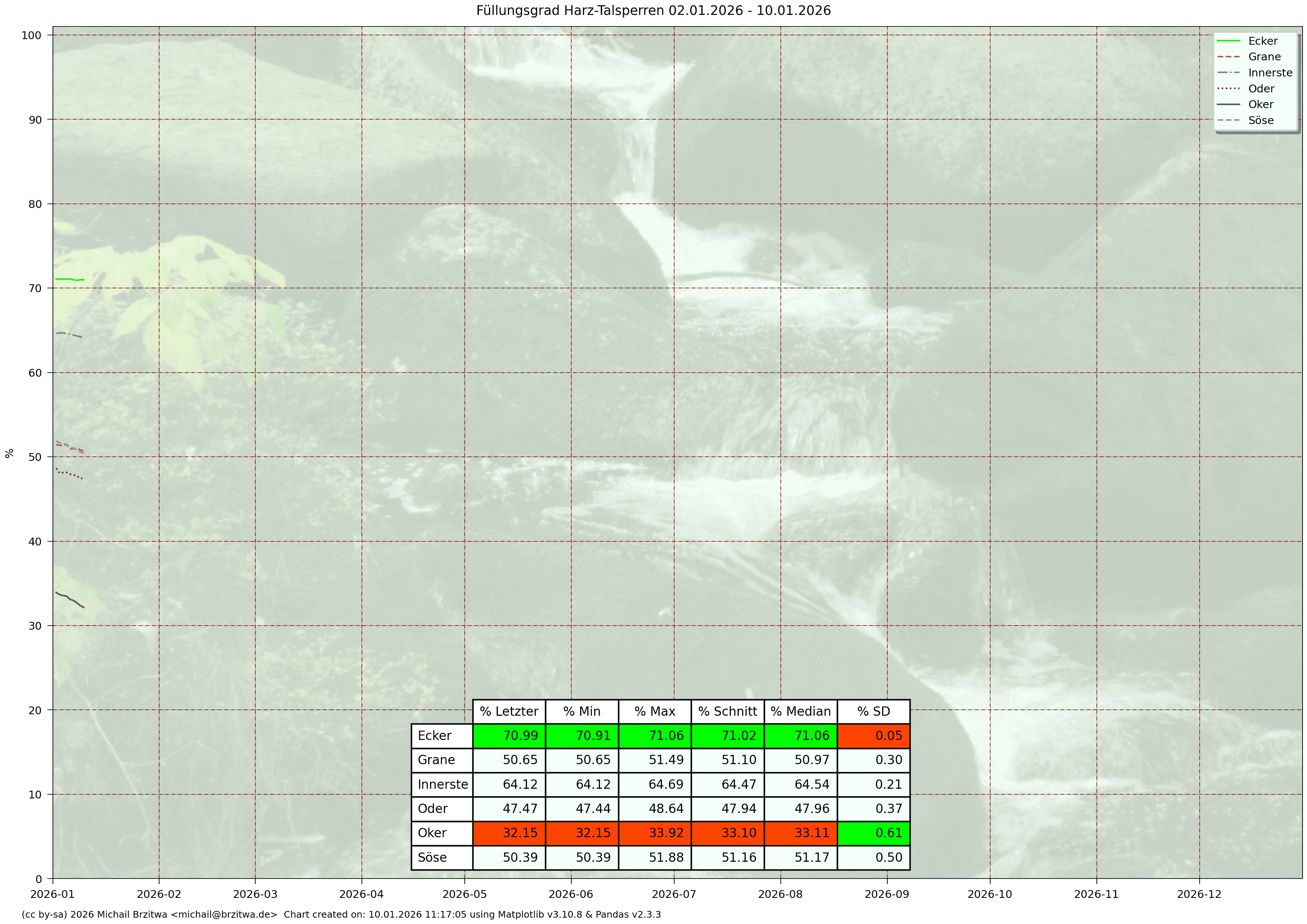
Relative Stauinhalte Harzer Talsperren 2026
|
Ende Februar 2022 stieg erstmals wieder seit März 2019 der Füllstand aller sechs Talsperren gleichzeitig über 80%. Der Pegel der Granetalsperre wird wie schon in 2020 auf einem hohen Niveau gehalten (Regelung über Abfluß in die Grane und Zufluß durch Oker- und Innerstetalsperre).
In Q1 2023 sind die Pegel der Talsperren bis auf die Innerste wieder über 80% gestiegen, im April der der Granetalsperre zum ersten Mal seit etwa fünf Jahren auf ca. 95%. Wegen des eher gemäßigt zu nennenden Frühsommers hier im Norden Deutschlands konnte der Füllstand der Granetalsperre noch bis in den Juli 2023 hinein hoch gehalten werden.
Durch den Dauerregen im letzten Quartal 2023 stiegen die Pegel der abgehenden Flüsse stark an. Die Harzwasserwerke waren sicherlich schon seit Oktober mit der Planung des Hochwasserschutzes im Winter und Frühjahr 2023/2024 beschäftigt gewesen.
Die erste Hälfte 2024 zeichnete sich durch eher moderate Abnahmen der Füllstände aus, natürlich aufgrund der Höchststände nach besagtem Weihnachtshochwasser. Die Pegelstandsregelung insbesondere der Granetalsperre zeigt das Bemühen der Harzwasserwerke, einer wahrscheinlich durch den Klimawandel bedingten, höheren Wetterdynamik strategisch Herr zu werden.
Das Jahr 2025 war wiederum geprägt von niedriger Zuflußmenge, und durch einen normalen Sommer, also keine überdurchschnittlichen Hitzewellen, bedingt moderate Entnahmen.
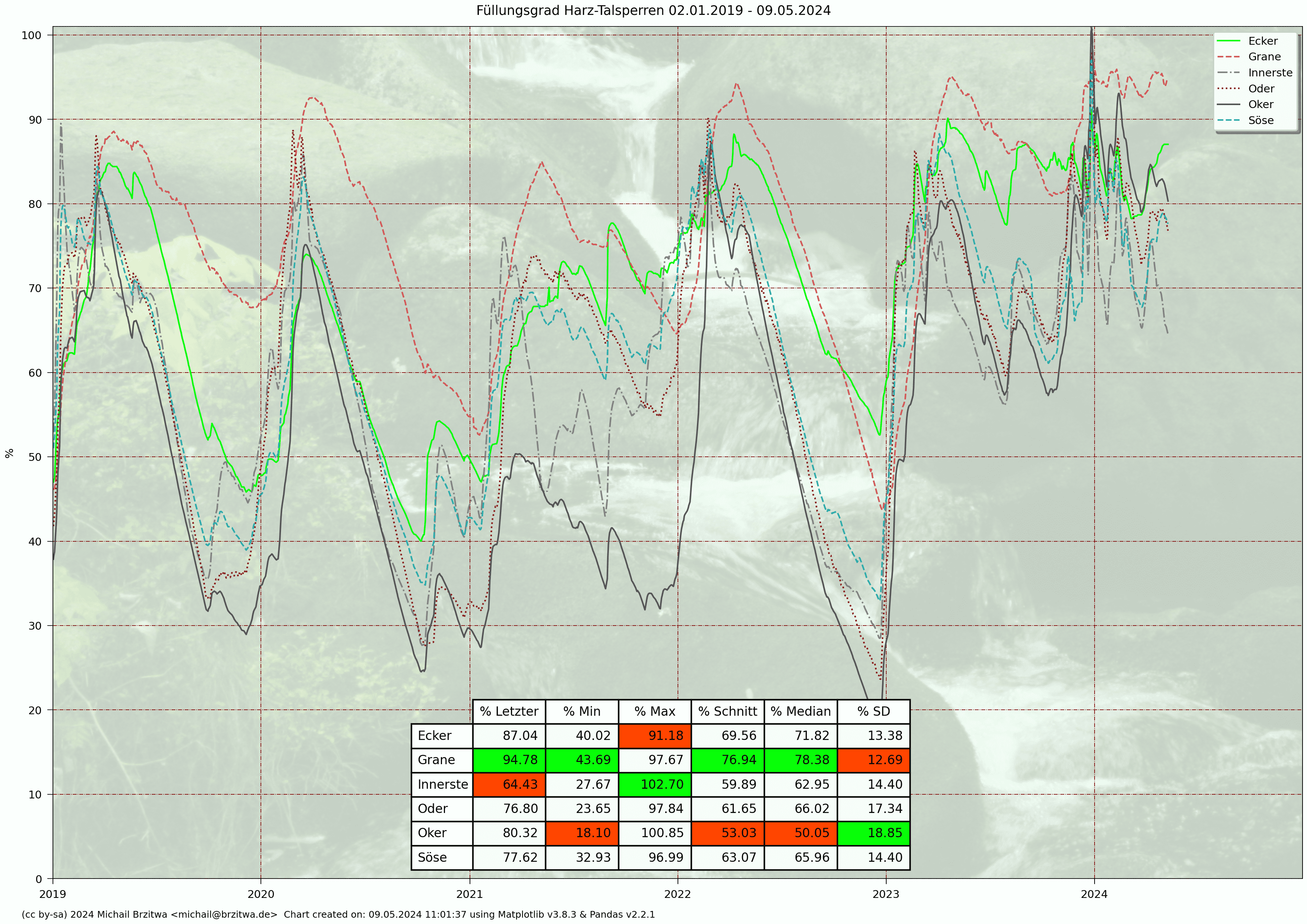
Relative Stauinhalte Harzer Talsperren 2020 - 2026
|
Wie in den einzelnen Jahresgraphen oben wird auch hier deutlich, dass der Füllungsgrad der Granetalsperre im Jahresmittel am höchsten ist, mit einem durchschnittlichen Füllungsgrad von ca. 78% etwa sieben Prozentpunkte über dem der restlichen Talsperren. Die Daten zeigen gut, dass die Granetalsperre auch durch ihre Verbindungen mit den anderen Talsperren als "Rückgrat" der Trinkwasserversorgung konzipiert wurde: ein relativ grosses und auf hohem Stand stabilisierbares Volumen, das auch dann noch beansprucht werden kann, wenn die Wasserstände der anderen Stauseen durch eine längere Trockenperiode schon weit abgesunken sind, und diese wieder verstärkt andere Aufgaben wie die Niedrigwasseraufhöhung übernehmen müssen.
5. Jahresvergleiche der Stauinhalte
Um die Entwicklung der Stauinhalte jahres- oder monatsweise vergleichen zu können, hier zuerst Plots der Jahresdifferenzen der Stauinhalte aller sechs Talsperren, beginnend mit dem Jahr 2020 im Vergleich zu 2021:
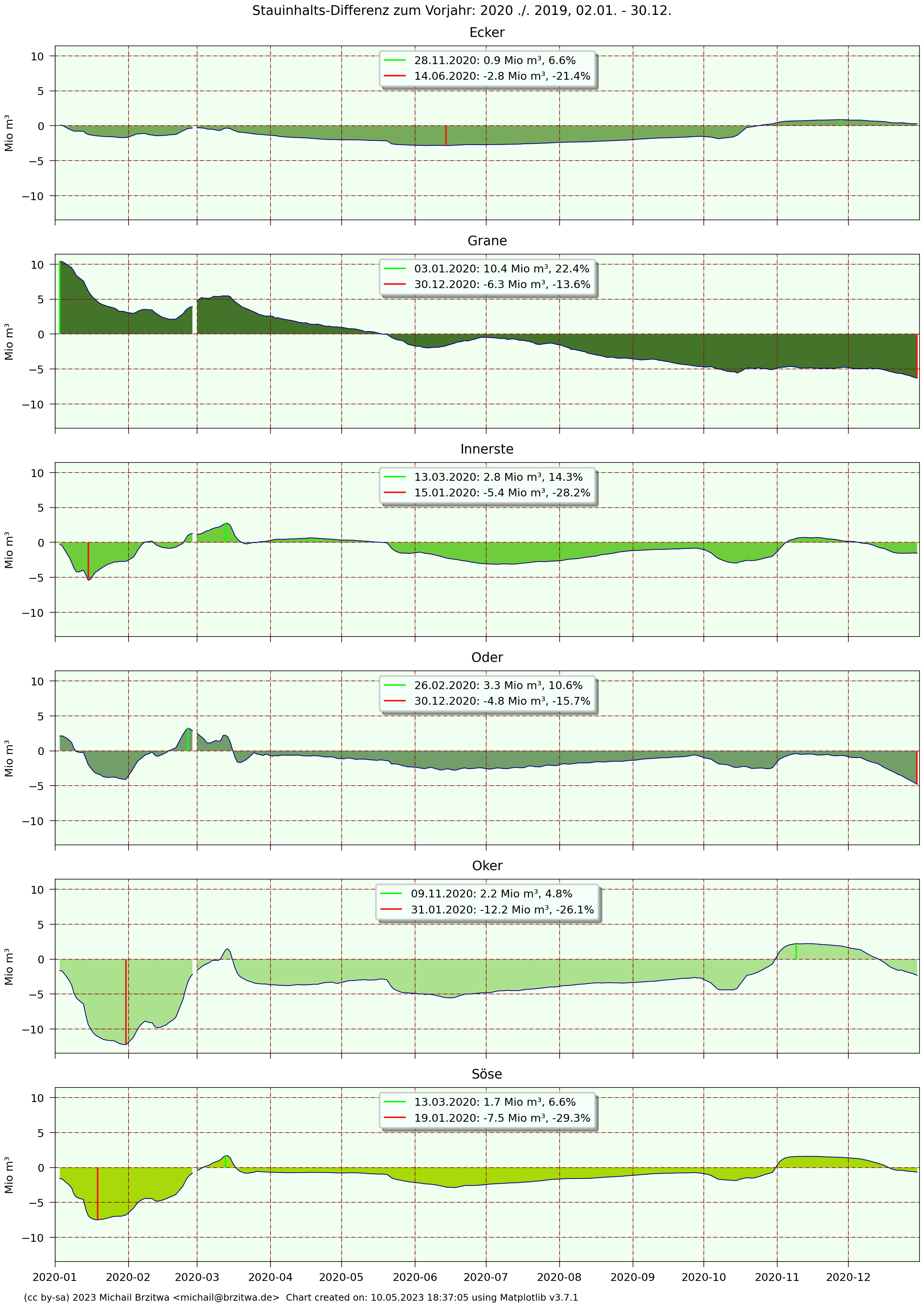
Stauinhalts-Differenz zum Vorjahr: 2020 zu 2019
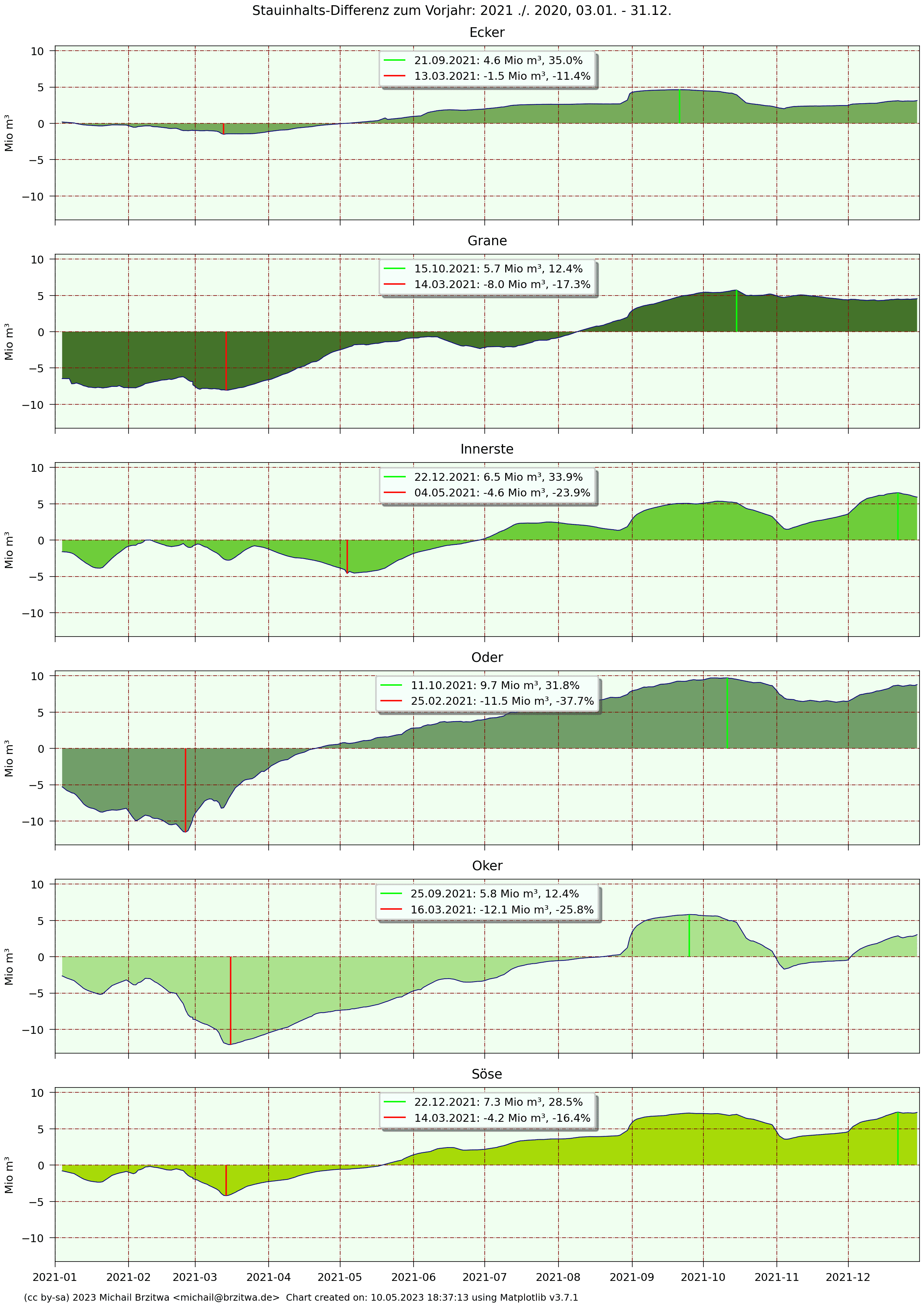
Stauinhalts-Differenz zum Vorjahr: 2021 zu 2020
|
An der Jahresdifferenz 2020 zu 2019 wird sichtbar, wie in 2020 die Stauinhalte im Vergleich zum Vorjahr hauptsächlich weniger zunahmen oder sogar mehr abnahmen, insbesondere ab etwa Mitte März 2020. Daraus resultierte wie oben angeführt dann ein durchschnittlicher Gesamtinhalt von 104 Mio m³ in 2020, mehr als. 9 Mio m³ weniger als in 2019.
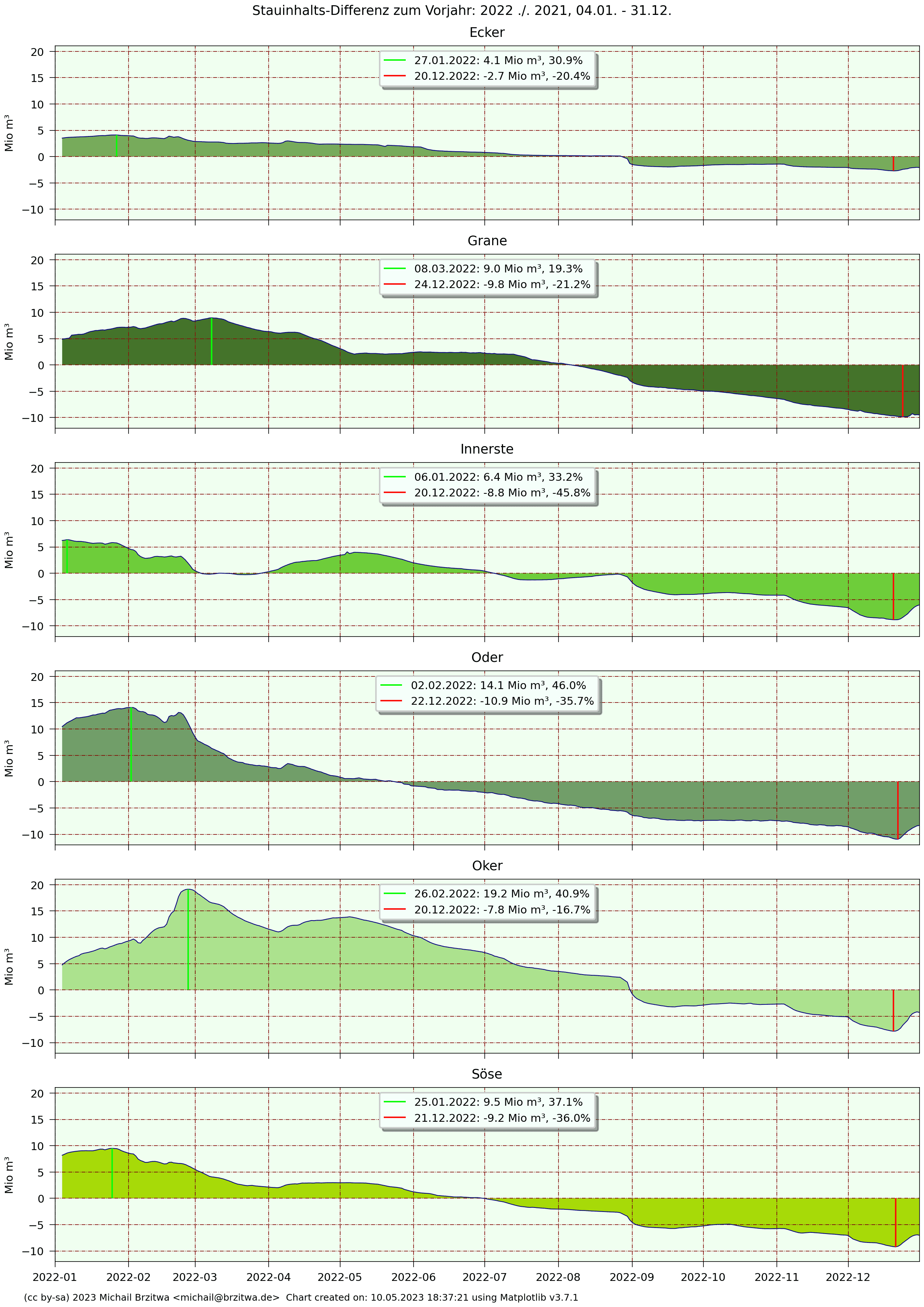
Stauinhalts-Differenz zum Vorjahr: 2022 zu 2021

Stauinhalts-Differenz zum Vorjahr: 2023 zu 2022
|
Das Jahr 2021 brachte im Vergleich zu 2020 dann offenbar etwas Entspannung: zwar stiegen die Stauinhalte im ersten und teilweise auch zweiten Quartal 2021 nicht so hoch wie noch in 2020, dann aber wurden die Differenzen zum Vorjahr immer positiver, der weniger heiße Sommer und etwas feuchtere Herbst 2021 sorgten für mehr Niederschlag, weniger Verbrauch und Verdunstung und damit letztlich für höhere Stauinhalte als 2020.
Die Sprünge Anfang September der Jahresdifferenzen 2022 zu 2021 liegen nicht an einem überdurchschnittlichen Abfluß im September 2022, sondern an starken Niederschlägen und somit Zuflüssen in diesem Monat in 2021.
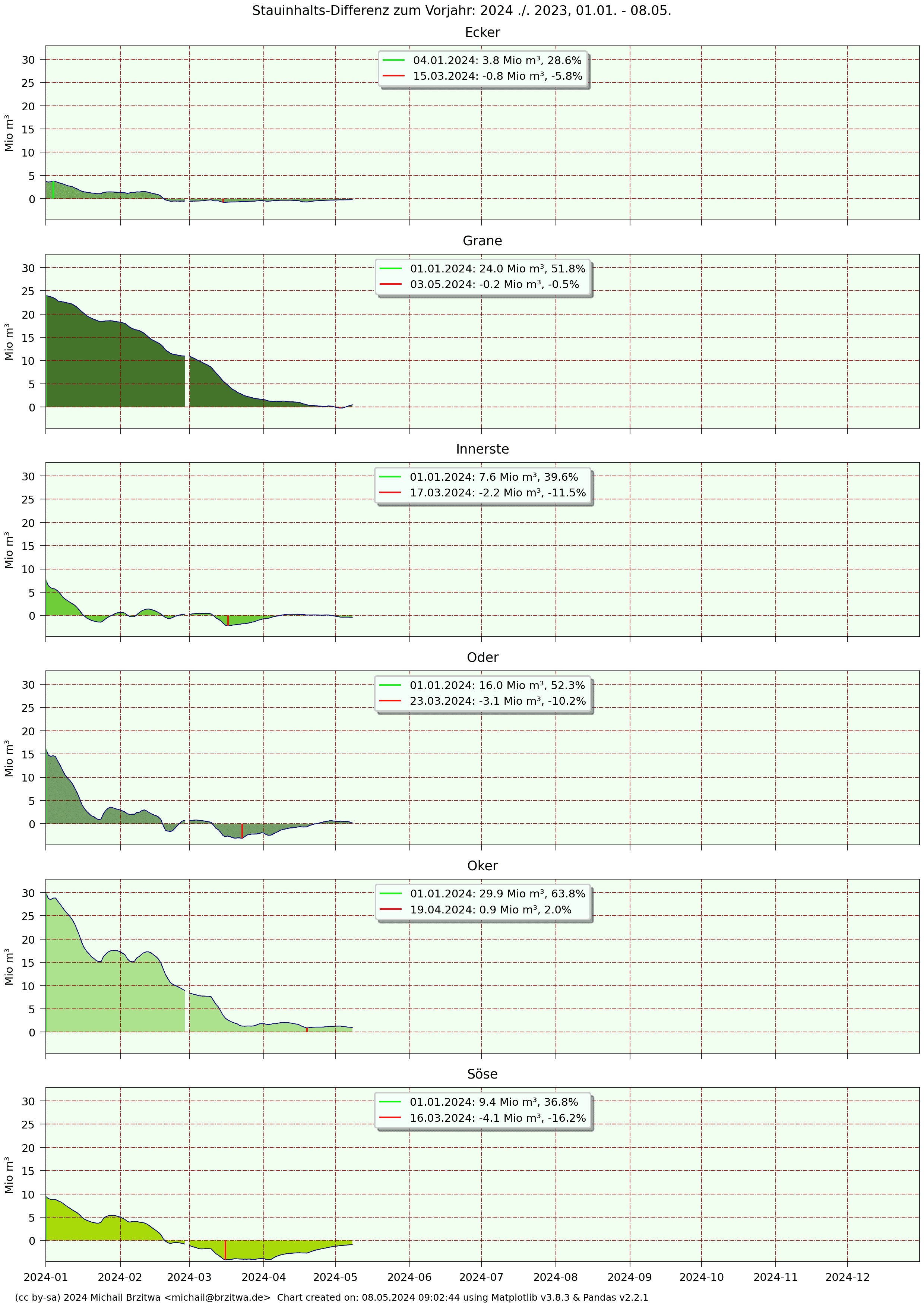
Stauinhalts-Differenz zum Vorjahr: 2024 zu 2023

Stauinhalts-Differenz zum Vorjahr: 2025 zu 2024
|
Die Entwicklung der Pegelstände 2023 im Vergleich mit 2022 kann als mengenmäßig durchweg positiv beurteilt werden. Wäre der Sommer 2023 ähnlich trocken wie 2022 gewesen, hätte das Stauvolumen trotzdem für die Trinkwasserversorgung und gegebenenfalls Niedrigwasseraufhöhung ausgereicht.
Mir ist nicht bekannt, ob der Trinkwasseranteil der Harzer Talsperren an der gesamen Wasserversorgung des Landes Niedersachsen mit der Zeit erhöht werden soll; sinkende Grundwasserspiegel sprächen eigentlich für eine solche mittel- und langfristige Anpassung. In welchem Maße sich die Entwicklung dieser Grundwasserspiegel durch das Weihnachtshochwasser 2023 entspannt hat, wird sich in den kommenden Jahren zeigen.
Die krassen Unterschiede der Füllstände im Vergleich 2024 zu 2023 am Jahresanfang und -ende sind natürlich durch eben dieses Hochwasser zu erklären, exemplarisch beträgt die höchste Differenz bei der Okertalsperre Ende Dezember 2024 zu 2023 fast 30%.
Während 2024 sich noch durch vermehrten Zufluß auszeichnete, musste 2025 als ein eher niederschlagsarmes Jahr mit nur wenig Pegelsteigerungen bezeichnet werden, daher waren die Unterschiede zu 2024 gerade am Jahresende sehr groß.
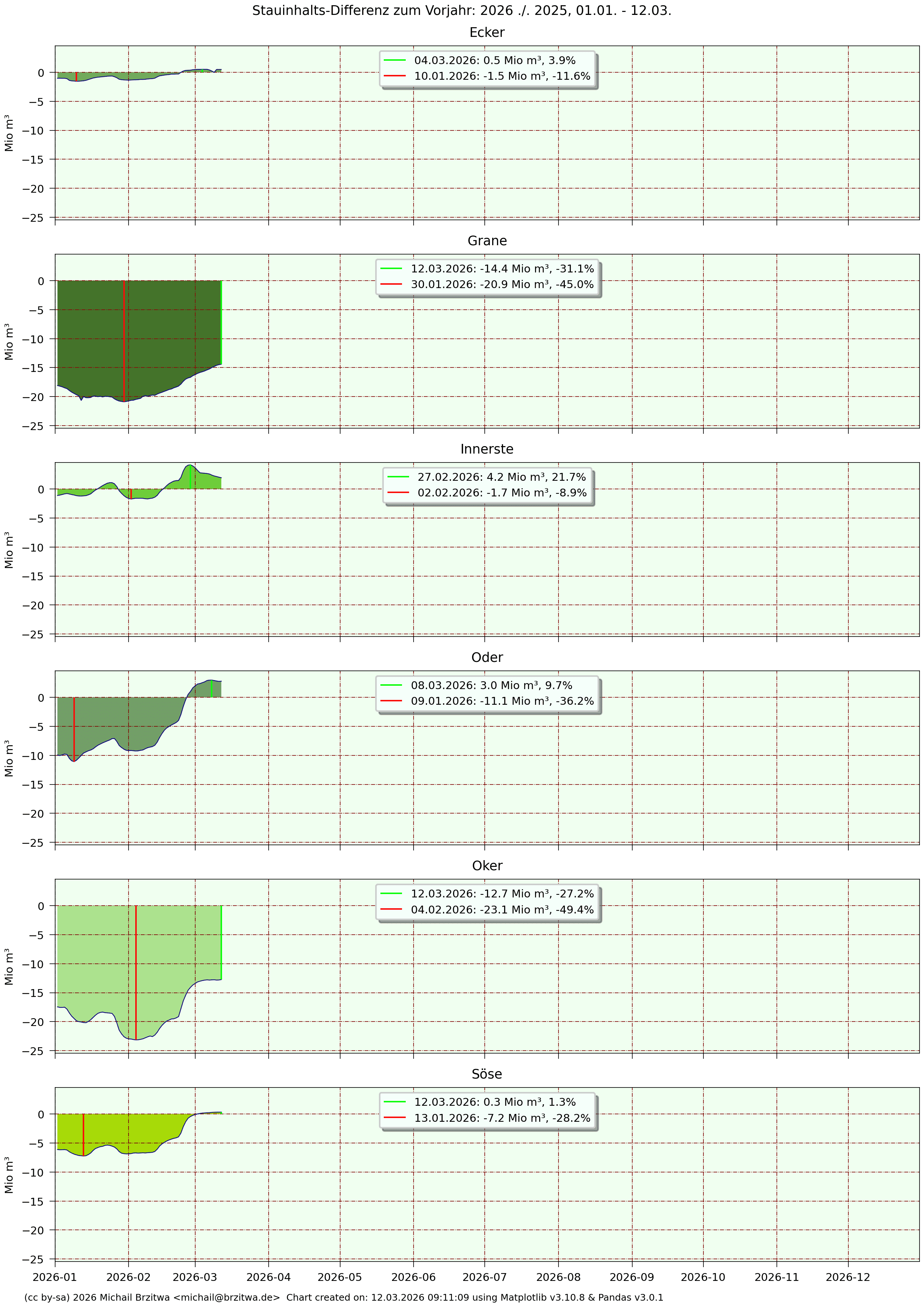
Stauinhalts-Differenz zum Vorjahr: 2026 zu 2025
|
Aufgrund der trockenen zweiten Jahreshälfte 2025 waren die Füllstände der sechs Talsperren am Jahresanfang 2026 ziemlich niedrig, daher resultierend die relativ hohen, negativen Differenzen zu den Jahresanfangsständen 2025.
6. Tabellarische Jahres-Bewertung
Ein weiterer Blickwinkel auf das Jahresverhalten der Füllstände wäre die Zahl der Tage, an denen die Summe der Stauinhalte gleich bleibt oder steigt, also der Stand am Tag X größer gleich ist als am Tag X-1, im Vergleich zu den Tagen, an denen der Inhalt abnimmt (Stand 28.02.2026):
| Jahr | Verfügbare Tagesdaten | Stauinhalt gleich oder zunehmend | Abnehmend | Verhältnis zunehmend/abnehmend |
|---|---|---|---|---|
| 2018 | 39 | 11 | 28 | 0,39 |
| 2019 | 230 | 74 | 156 | 0,47 |
| 2020 | 189 | 65 | 124 | 0,52 |
| 2021 | 231 | 100 | 131 | 0,76 |
| 2022 | 301 | 73 | 228 | 0,32 |
| 2023 | 346 | 156 | 190 | 0,82 |
| 2024 | 338 | 107 | 231 | 0,46 |
| 2025 | 335 | 69 | 266 | 0,26 |
| 2026 | 58 | 31 | 27 | 1,87 |
Da mir über das Jahr zum Teil nur wenige Daten vorliegen, in 2020 zum Beispiel nur an 189 von 366 Tagen, ist das obige Verhältnis nur begrenzt aussagefähig. Trotz dieser Einschränkung kann man wagen, Tendenzen zu benennen: 2021 war hinsichtlich der Wasserstände der Harzer Talsperren ein relativ positives Jahr: viel Zu- und relativ wenig Abfluß. 2022 dagegen zeichnet sich durch eine durchweg negative Bilanz aus, nur wenige Tage mit Nettozufluß. Würde 2022 isoliert vom Vorjahr betrachtet, müsste man es als weitaus "trockener" als 2018 bezeichnen.
2023 dagegen entwickelte sich in puncto Regenmengen sehr positiv, wies im Vergleich zu den Jahren 2018 - 2022 die meisten Tage mit gleichbleibendem oder zunehmendem Gesamtpegel auf. 2023 war also hier in Norddeutschland mit Abstand das regenreichste Jahr seit 2018 sein.
2024 wiederum kann als gemäßigtes Jahr eingestuft werden, ähnlich 2019. Das Jahr 2025 dagegen war diesbezüglich das niederschlagsärmste seit 2018, an nur 69 von erfassten 335 Tagen stieg der summierte Stauinhalt aller sechs Talsperren.
Anfang 2026 dann gab es reichlich Schnee und später auch Niederschlag.
FYI: wie bei vielen anderen datenbasierten Aussagen hier steht am Anfang eine SQL-Abfrage der obengenannten PDF-Tagesdaten. Exemplarisch die Abfrage der Zahl der Tage mit zunehmendem Stauinhalt:
with ts_sumcontents as (
select mdate,sum(curcontent) as sumcontent
from ts_levels
group by mdate
order by mdate
), ts_lagcontents as (
select mdate,sumcontent,lag(sumcontent,1) over (order by mdate) as lagcontent
from ts_sumcontents
group by mdate,sumcontent
order by mdate
)
select date_part('year',mdate) as year,
count(mdate) as increasing_days
from ts_lagcontents
where sumcontent >= lagcontent
group by year
order by year;
Ausgabe dieser Abfrage (PostgreSQL):
year | increasing_days ------+----------------- 2018 | 11 2019 | 74 2020 | 65 2021 | 100 2022 | 73 2023 | 156 2024 | 107 2025 | 69 2026 | 31 (9 Zeilen)
Offensichtlich müssen 2022 und insbesondere 2025 nach 2018 als weitere Trockenjahre bezeichnet werden. In den Einzeldarstellungen der sechs Talsperren kann abgelesen werden, wie gering die bisherigen Niederschläge an den Talsperren (nur an den Sperren, nicht im Einzugsgebiet, dafür fehlen mir die Daten) in 2022 und 2025 ausfielen:
| Zeitraum | Ecker | Grane | Innerste | Oder | Oker | Söse | Summe |
|---|---|---|---|---|---|---|---|
| 2019 | 2,21 | 1,90 | 2,35 | 2,51 | 3,02 | 2,57 | 14,56 |
| 2020 | 2,42 | 1,77 | 2,32 | 2,28 | 3,02 | 2,26 | 14,07 |
| 2021 | 2,14 | 1,86 | 2,46 | 2,13 | 2,92 | 2,30 | 13,81 |
| 2022 | 1,50 | 1,54 | 1,81 | 1,99 | 2,37 | 1,80 | 11,01 |
| 2023 | 3,17 | 3,08 | 3,55 | 3,82 | 4,71 | 3,35 | 20,68 |
| 2024 | 2,47 | 2,65 | 2,89 | 3,22 | 3,75 | 2,88 | 17,86 |
| 2025 | 1,32 | 0,73 | 1,75 | 1,79 | 1,98 | 1,39 | 8,96 |
| 2026 | 2,02 | 2,21 | 2,95 | 3,71 | 3,26 | 2,53 | 16,68 |
Bemerkenswert hierbei, dass es, wie schon erwähnt, in 2025 keine Hitzewellen im Bereich des Harzes wie in 2022 gab, dass also die 2025er Verdunstung an den sechs Talsperren nicht so hoch wie in 2022 gewesen sein kann.
7. Aktuelle Tagesdifferenzen der Stauinhalte
An den Graphen der jährlichen Stauinhalte lassen sich tagesweise Veränderungen nur schwer ablesen, deshalb hier die geplotteten Tagesdifferenzen der Stauinhalte der Talsperren (also immer Stauinhalt an Tag X minus Inhalt am Tag X-1):
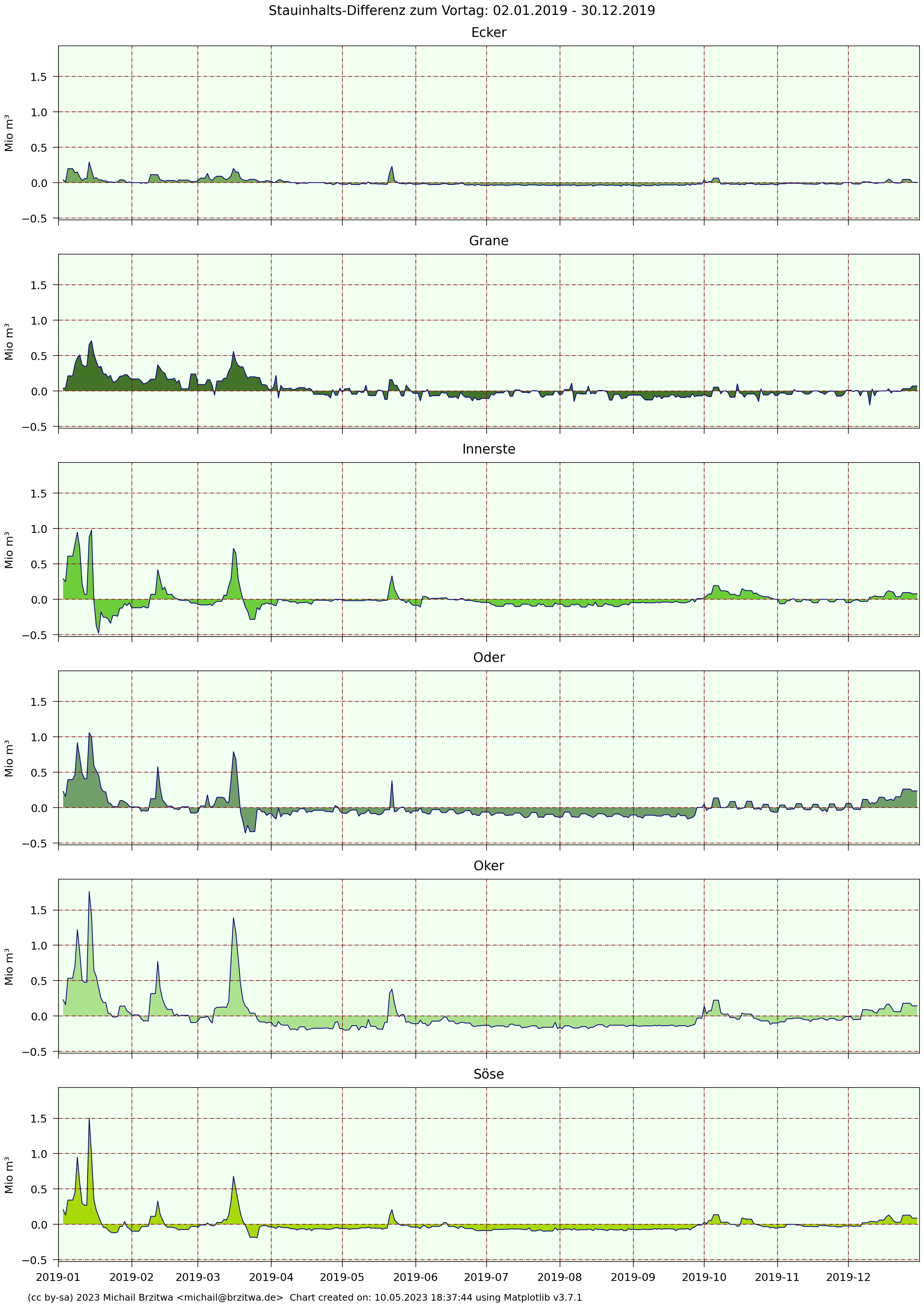
2019 Tagesdifferenzen Stauinhalte Harzer Talsperren
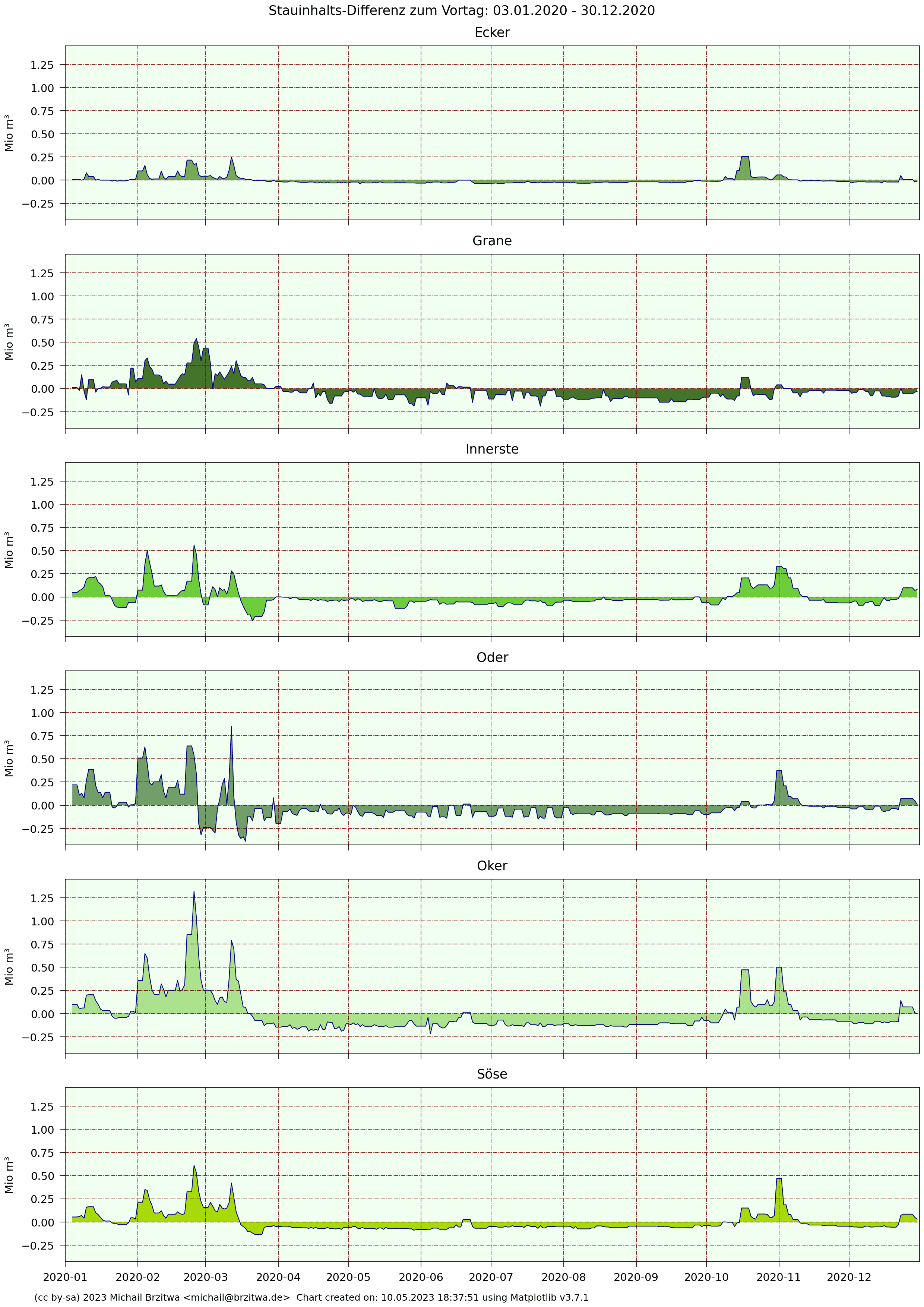
2020 Tagesdifferenzen Stauinhalte Harzer Talsperren
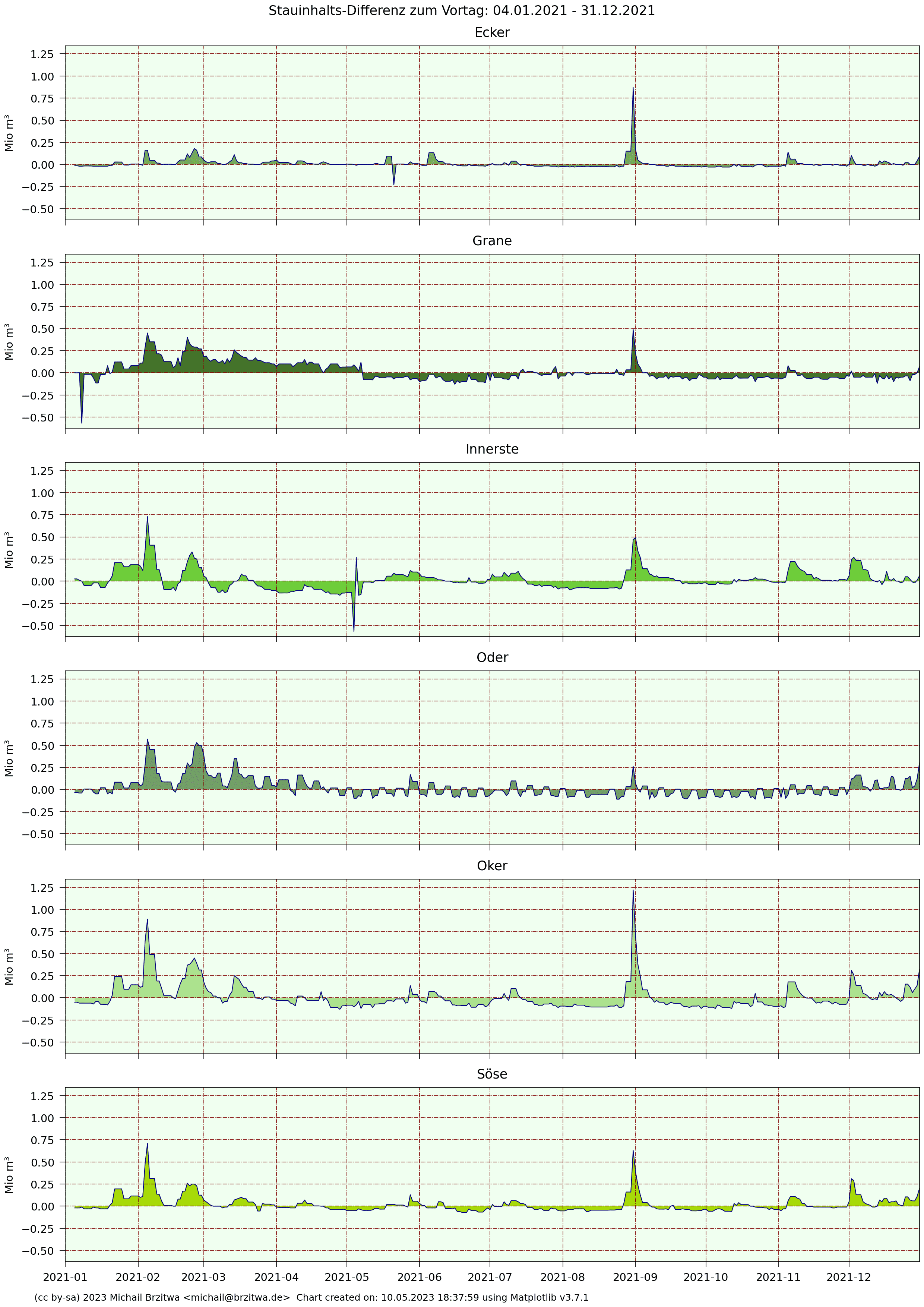
2021 Tagesdifferenzen Stauinhalte Harzer Talsperren
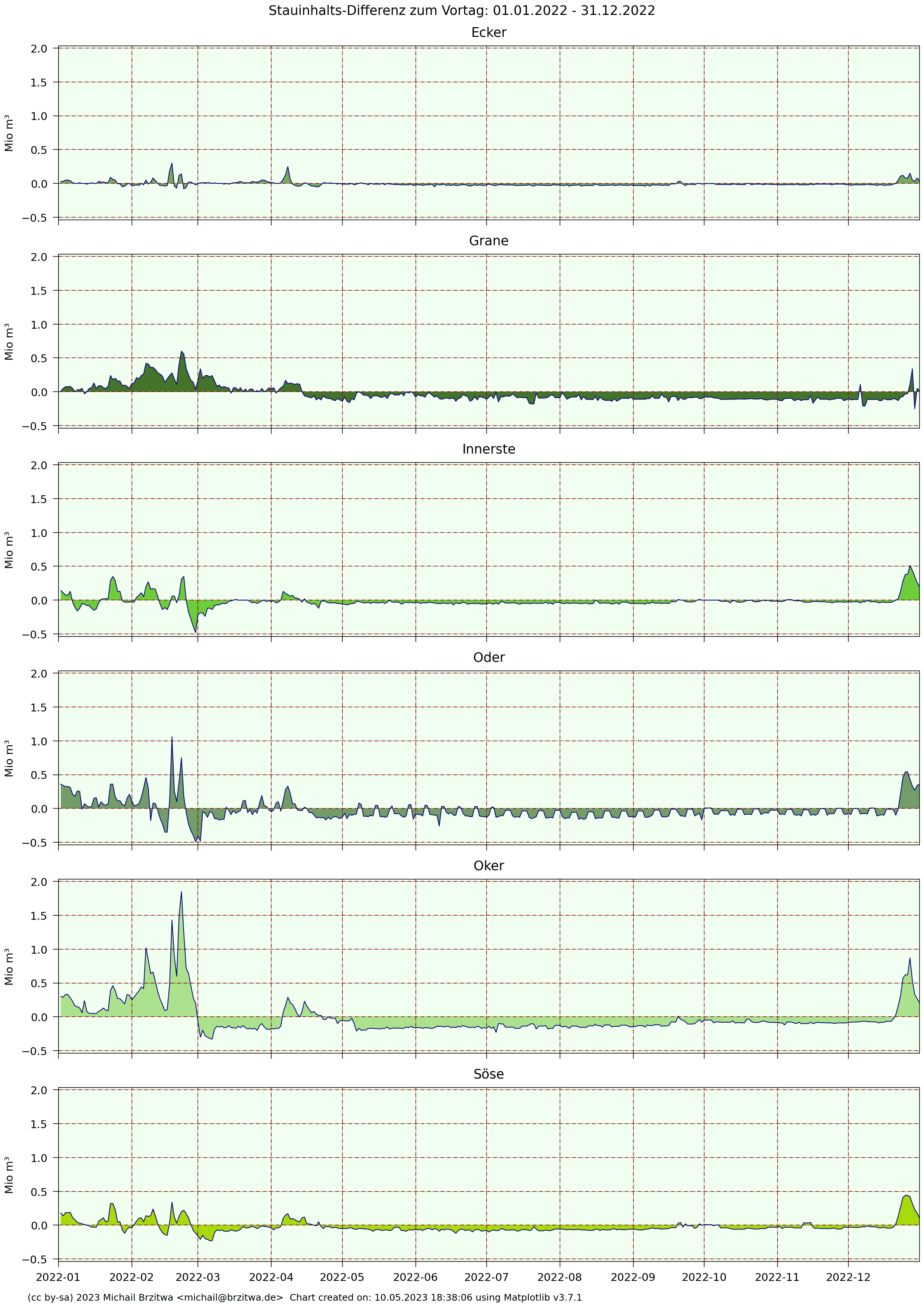
2022 Tagesdifferenzen Stauinhalte Harzer Talsperren
|
Im Prinzip zeigen diese Kurven also die zeitlichen Ableitungen der absoluten Stauinhalte, oder andersrum die Stauinhalte die Integrale dieser Tagesdifferenzen 😁.
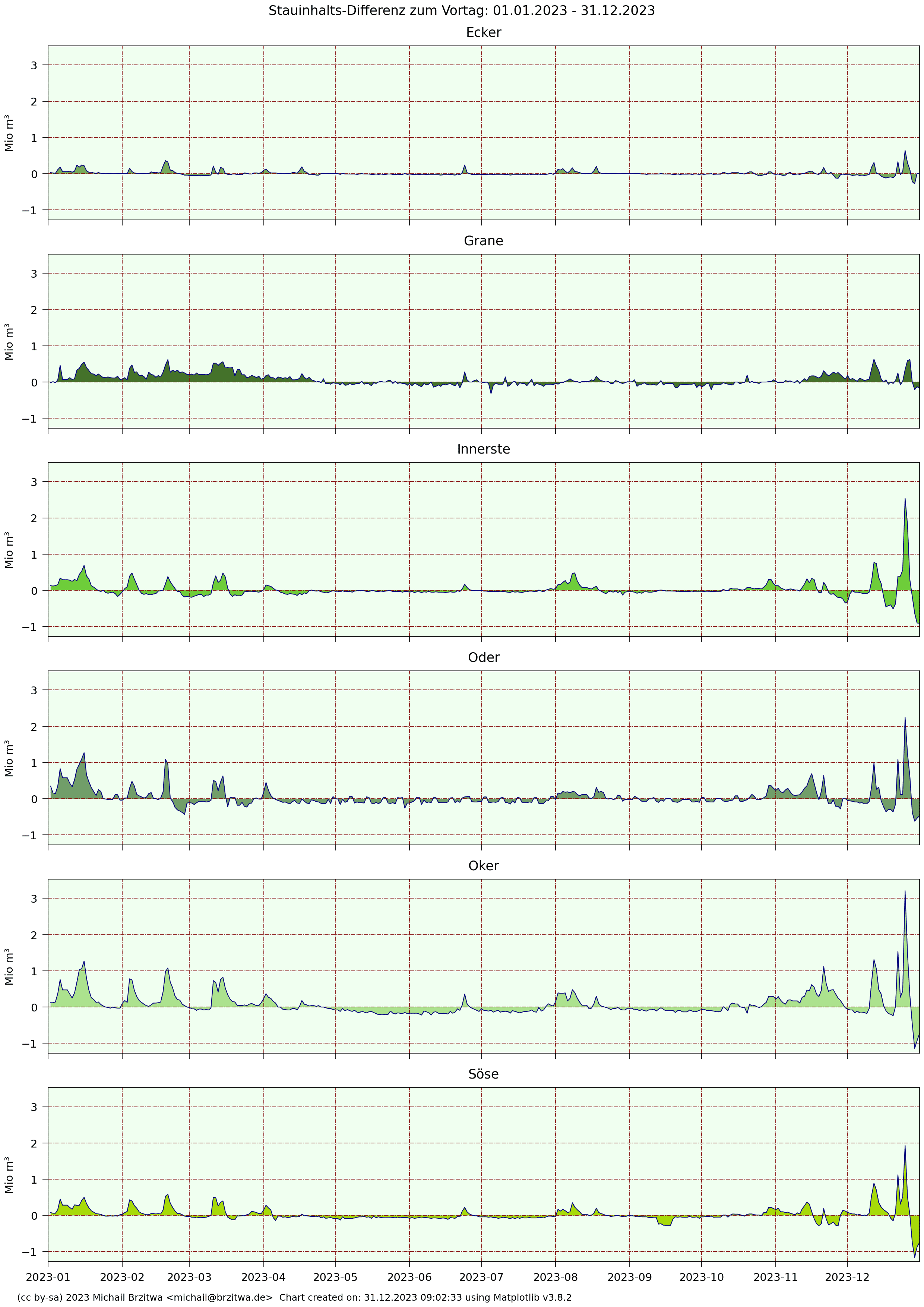
2023 Tagesdifferenzen Stauinhalte Harzer Talsperren
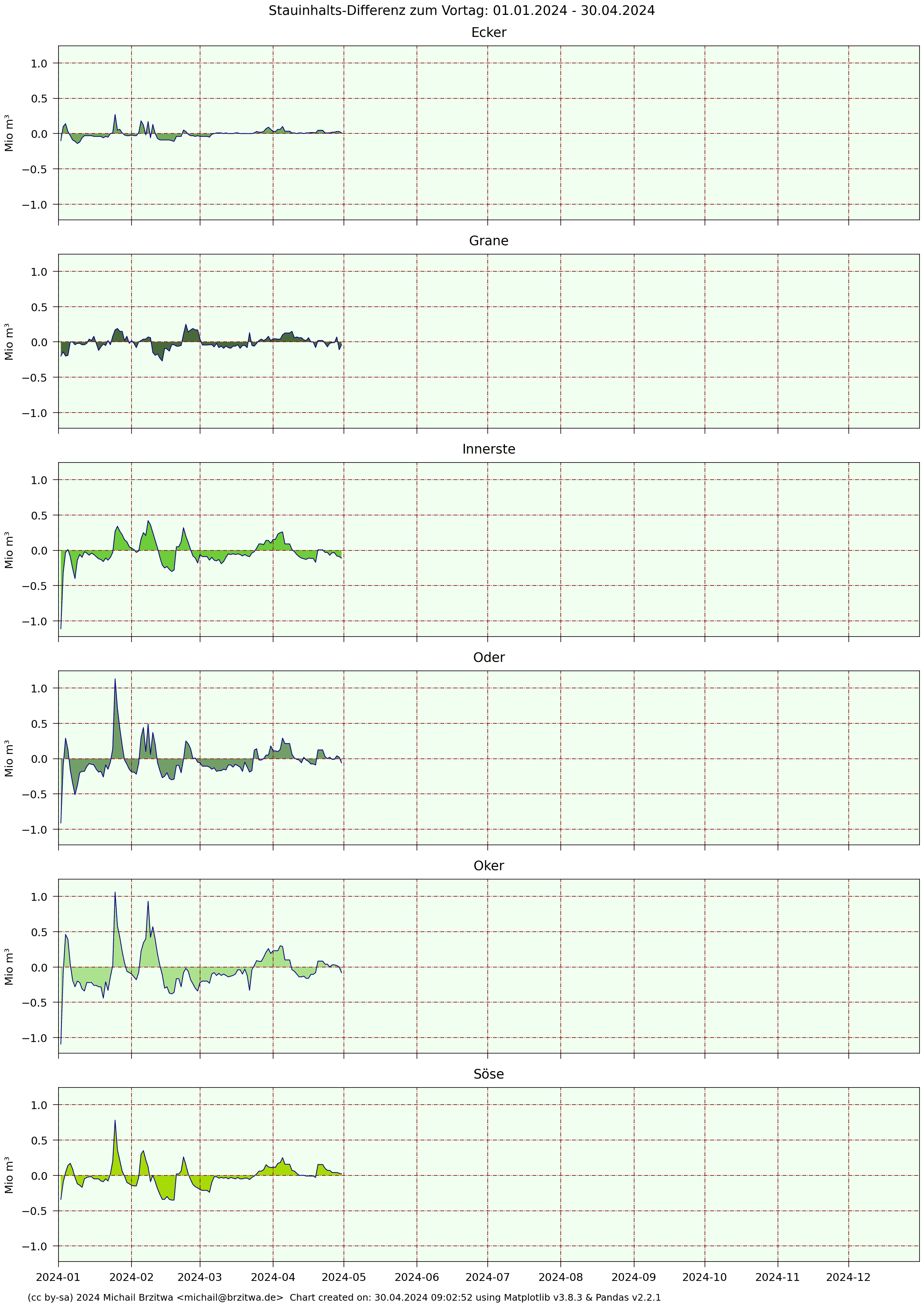
2024 Tagesdifferenzen Stauinhalte Harzer Talsperren

2025 Tagesdifferenzen Stauinhalte Harzer Talsperren
2026 Tagesdifferenzen Stauinhalte Harzer Talsperren
|
Bemerkenswert hier das "Rechtecksignal" der Odertalsperre, eine Art "Entnahmetaktung" in den Sommer- und Herbstmonaten: etwa alle drei bis vier Tage verringert sich die Entnahme bzw der Abfluss um einen geringen, aber halbwegs konstanten Wert (~0,1 Mio m³), um dann nach weiteren vier Tagen wieder um diesen Wert zu steigen. Ich habe keine Ahnung, was der Zweck dieser Übung sein könnte, ob dem ein natürliches Phänomen oder aktiver Regeleingriff der Harzwasserwerke (weit wahrscheinlicher) zugrunde liegt.
Die Tagesdifferenzen im gesamten Erfassungszeitraum:
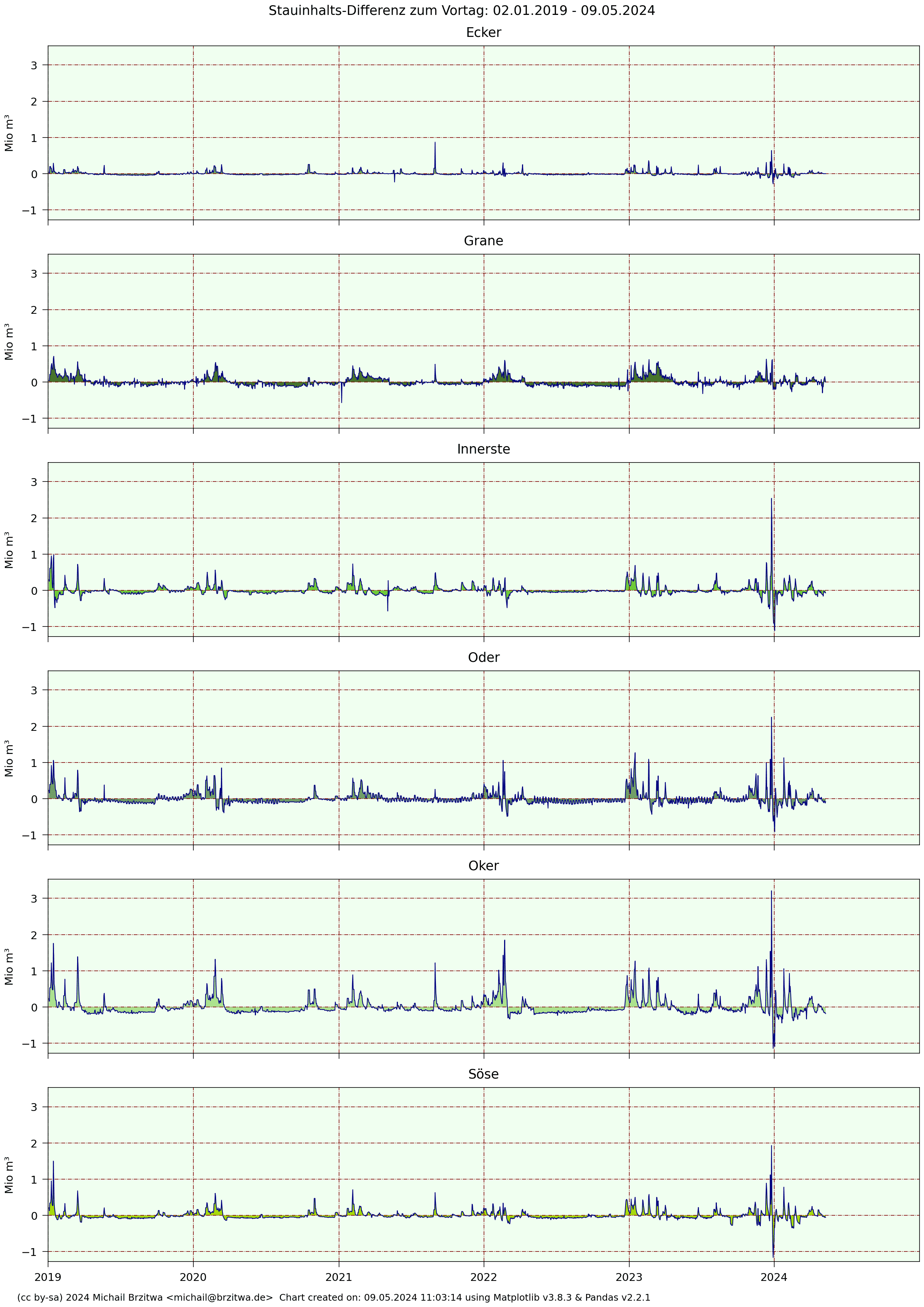
2020 - 2026 Tagesdifferenzen Stauinhalte Harzer Talsperren
|
8. Detaillierte Einzeldarstellungen aller sechs Talsperren
Neben den oben gezeigten Entwicklungen der Stauinhalte enthält die Datenbasis auch die Werte des Niederschlags, Zuflusses und der Unterwasser-Abgabe der einzelnen Talsperren. Für jede Talsperre habe ich diese Werte mit dem Stauinhalt in Einzeldiagrammen grafisch übereinander dargestellt (Klick öffnet die Jahresaufschlüsselung auf einer eigenen, neuen Seite):
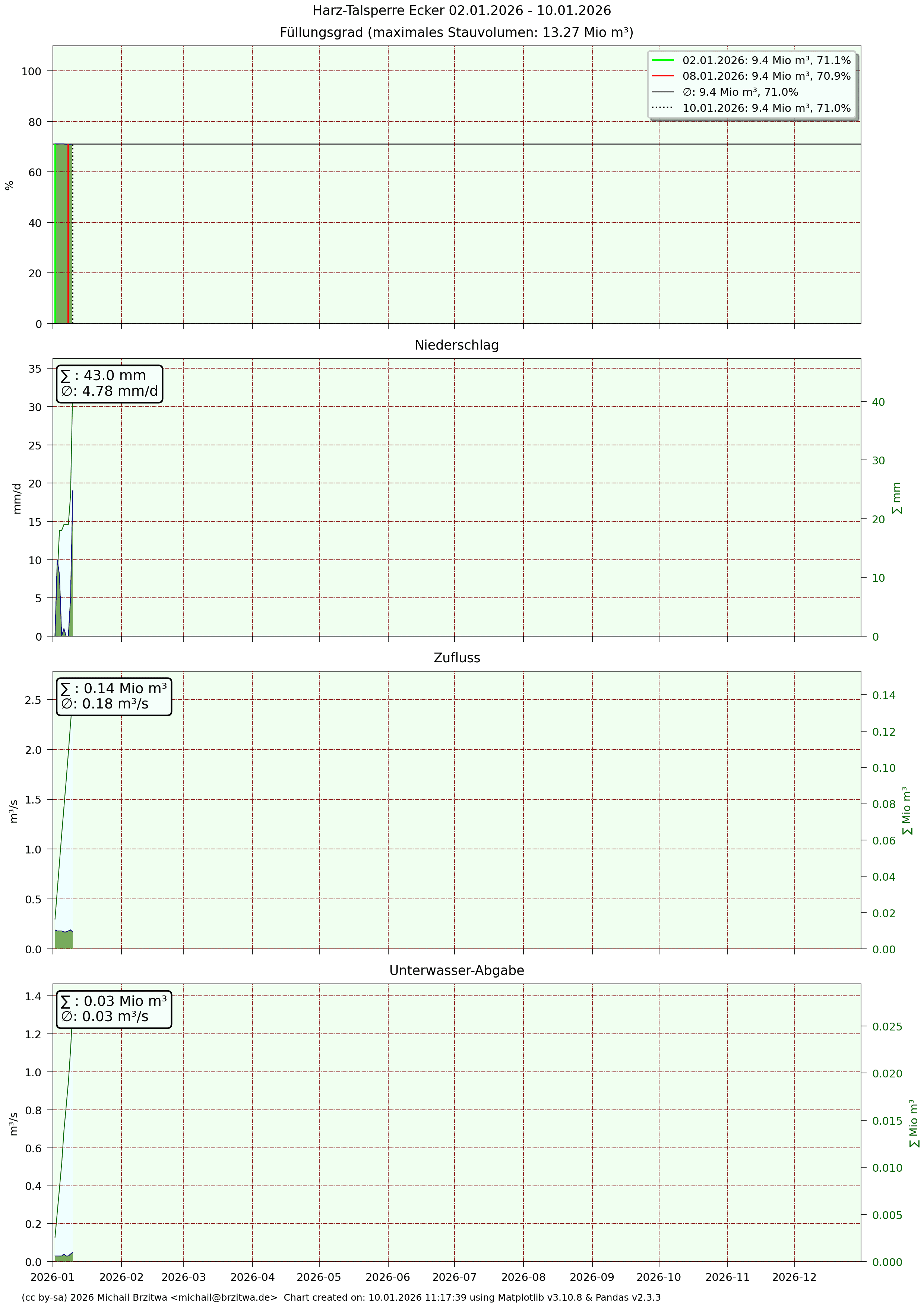
Detaildaten Eckertalsperre
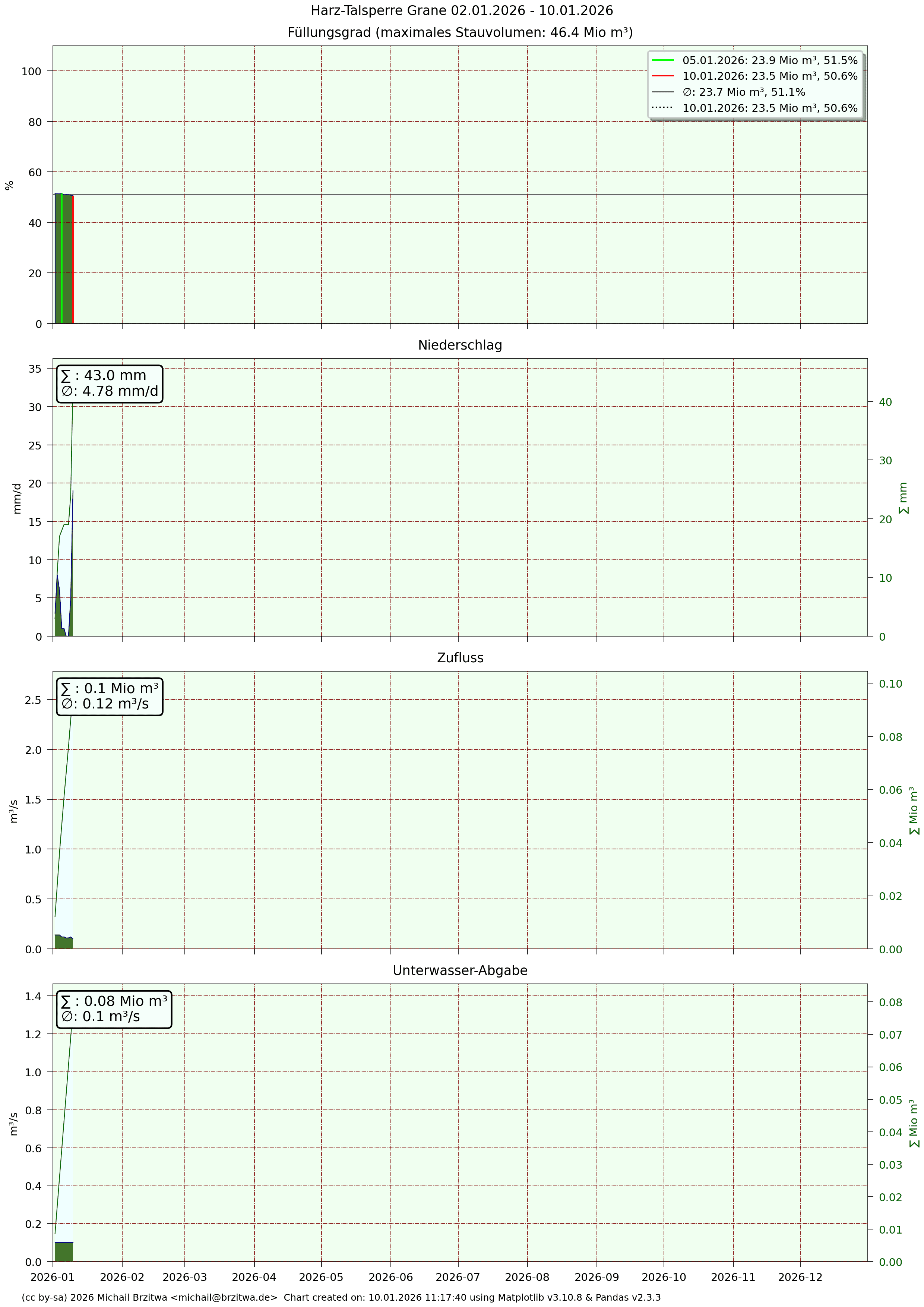
Detaildaten Granetalsperre
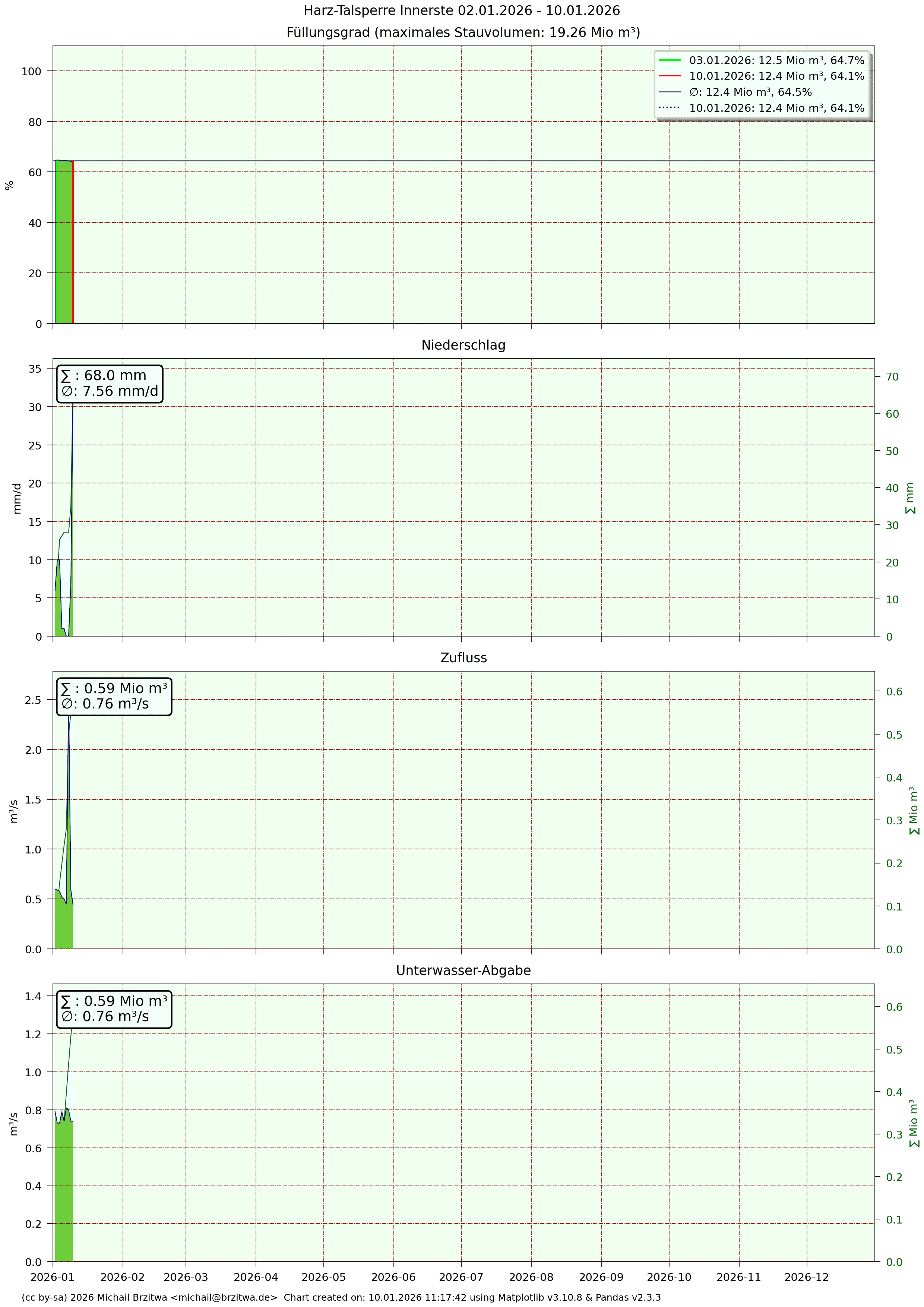
Detaildaten Innerstetalsperre
|
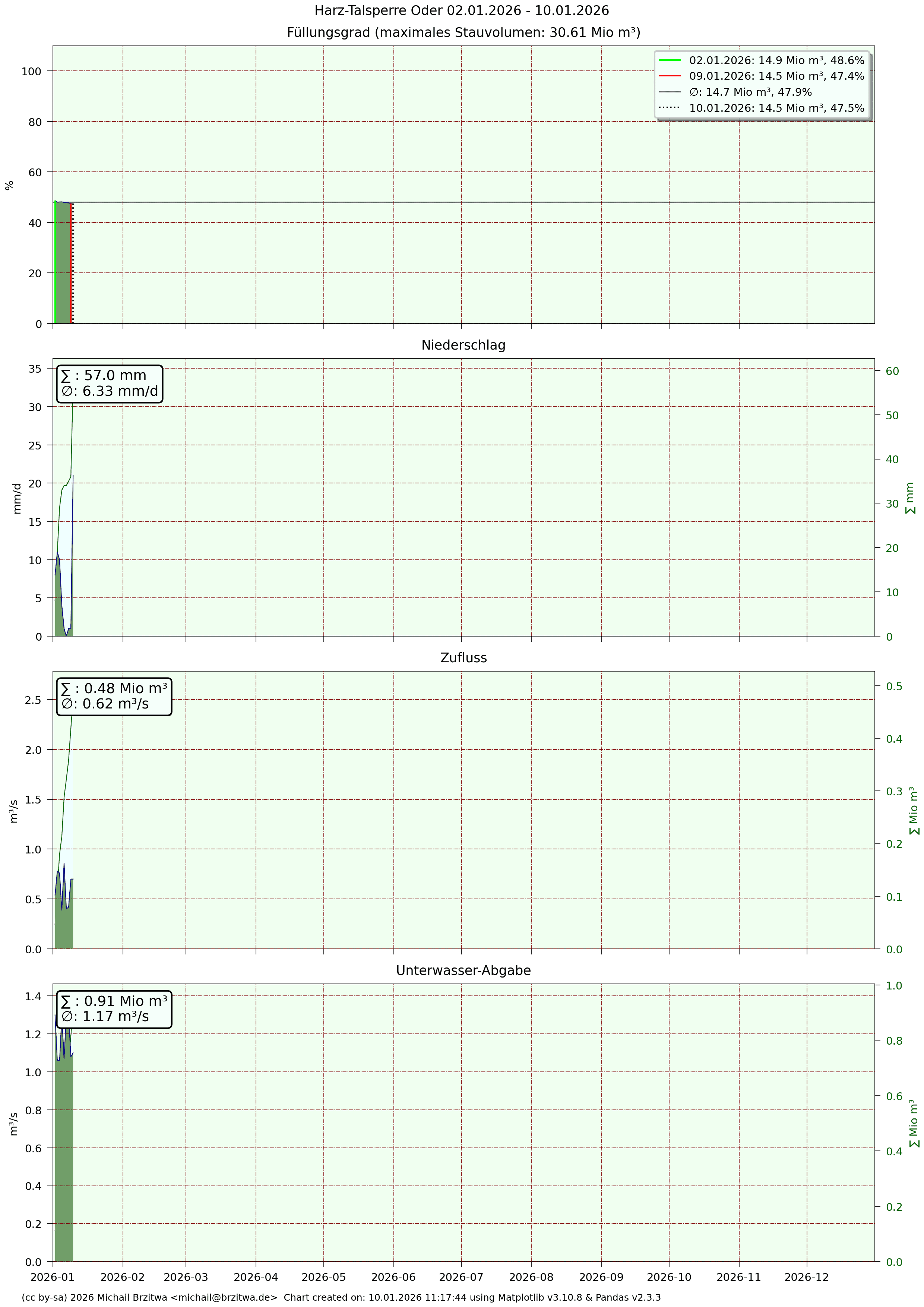
Detaildaten Odertalsperre
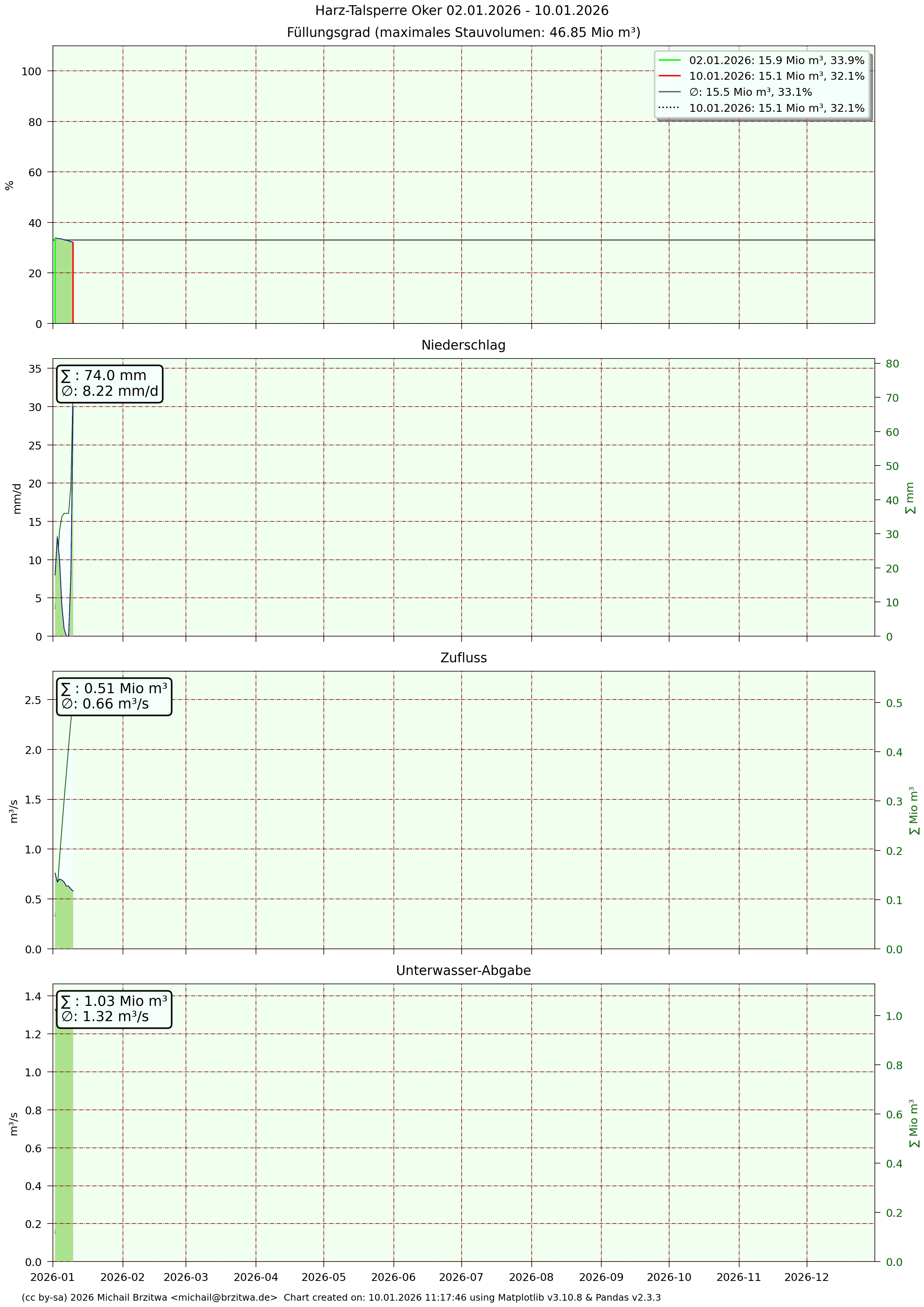
Detaildaten Okertalsperre
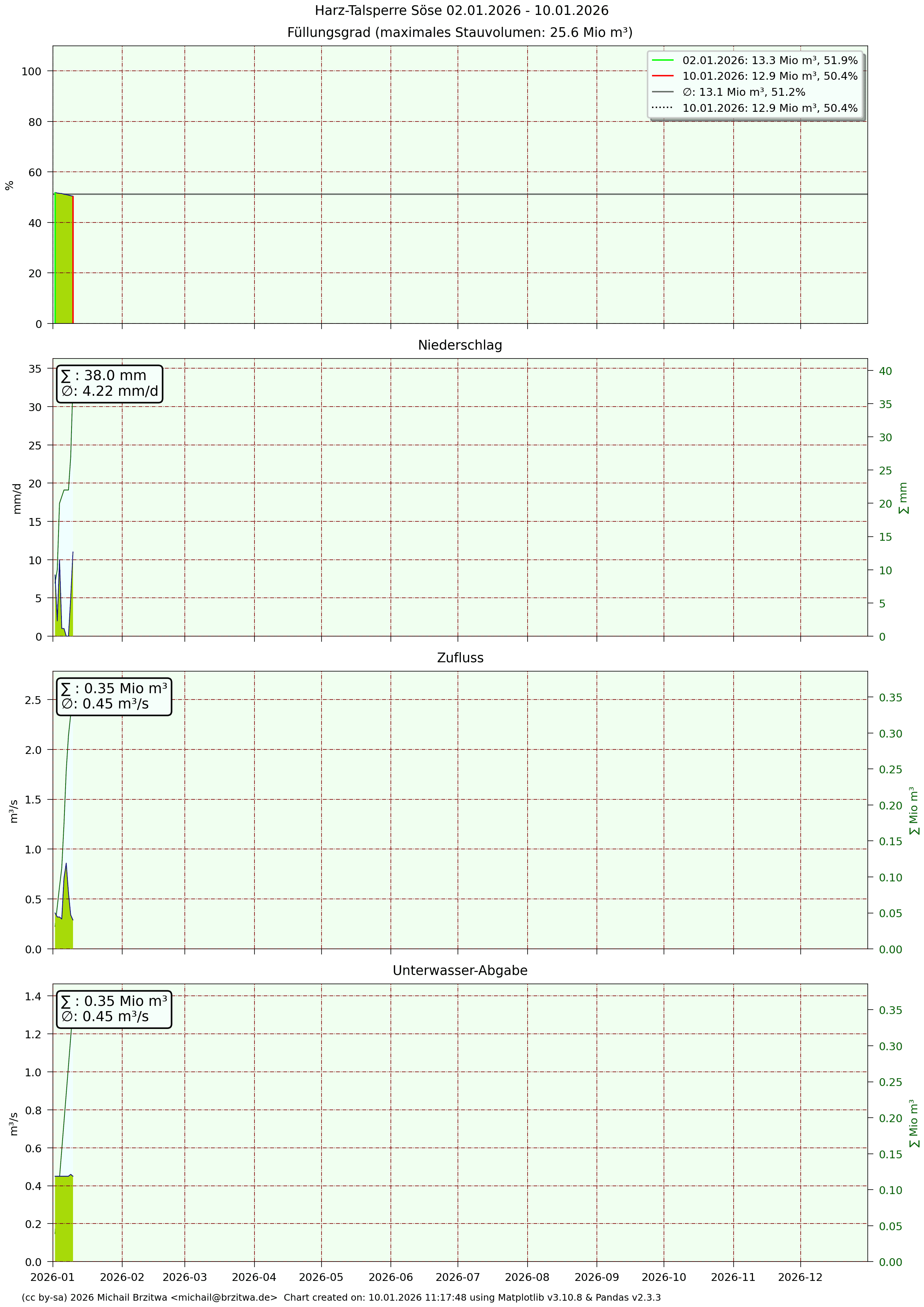
Detaildaten Sösetalsperre
|
Mir fiel beim ersten Hinsehen die zum Teil sehr unterschiedlichen Unterwasser-Abgaben auf: Grane- und Eckertalsperre haben sowohl die geringste aller sechs Unterwasser-Abgaben über die Jahre als auch die geringsten Schwankungen eben dieser.
Im Frühjahr 2022 erreichte der Pegel der Sösetalsperre mit ca. 85% seinen höchsten Stand seit zweieinhalb Jahren. Aufgrund der relativ schnell steigenden Pegel wurden Ende Januar bis Ende Februar 2022 von den Harzwasserwerken sukzessive die Unterwasserabgaben der Talsperren Oder, Söse, Ecker und Innerste verdreifacht. Ein Balanceakt offenbar: die Talsperren sollten zum Ende des ersten Quartals optimal gefüllt sein, um genügend Volumen für die Trinkwasserversorgung und Niedrigwasseraufhöhung in trockenen Jahreszeiten vorhalten zu können, andererseits sollten Hochwässer der Flüsse solange es geht vermieden werden. Die Füllung der Stauseen sollte aber auch nicht allzu schnell erfolgen, um in Perioden intensiveren Niederschlags noch ausreichend Puffervolumen zu besitzen.
Die Pegelstände der niedersächsischen Flüsse werden auf der "Pegelstandskarte des Länderübergreifenden Hochwasser-Portals" ständig aktualisiert.
Anfang bis Mitte März 2022 wurden die Unterwasserabgaben dann wieder auf ein Normalmaß zurückgefahren, da ab Ende Februar kaum noch Niederschlag fiel. Jährliche Extremwerte der gesamten Unterwasserabgaben aller sechs Harzer Talsperren von 2019 bis 2025:
| Jahr | Maximum am | Wert in m³/s | Minimum am | Wert in m³/s | Durchschnitt in m³/s | Median in m³/s |
|---|---|---|---|---|---|---|
| 2019 | 22.03. | 17,05 | 16.12. | 3,45 | 5,26 | 4,03 |
| 2020 | 28.02. | 17,26 | 03.02. | 3,35 | 5,20 | 3,92 |
| 2021 | 29.12. | 6,28 | 07.01. | 3,62 | 4,08 | 3,93 |
| 2022 | 24.02. | 27,76 | 21.12. | 3,42 | 6,19 | 4,07 |
| 2023 | 27.12. | 96,97 | 26.06. | 3,70 | 8,75 | 5,17 |
| 2024 | 01.01. | 63,94 | 30.07. | 3,67 | 8,70 | 5,02 |
| 2025 | 01.02. | 16,03 | 27.06. | 3,17 | 5,03 | 3,94 |
| 2026 | 23.02. | 17,21 | 24.01. | 3,63 | 5,00 | 4,08 |
Die UW-Abgaben in 2023 erreichten den höchsten Wert seit 2019, was natürlich der hohen Niederschlagsmenge dieses Jahres und folglich den höchsten Pegelständen seit mindestens 2017 zu verdanken war. Die 2024er Abgaben blieben weiterhin hoch, da zum einen der aufgrund des Hochwassers sehr hohe Pegelstand aller sechs Talsperren etwas abgebaut werden musste, und zum anderen über das gesamte Jahr leicht überdurchschnittlicher Zufluss hinzukam. Die aktuellen Unterwasserabgaben Stand 28.02.2026:
| Talsperre | Aktuell (m³/s) | Vortag (m³/s) | Minimum (m³/s) | Maximum (m³/s) | Durchschnitt (m³/s) | Durchschnittliche Tagesmenge (Mio m³) |
|---|---|---|---|---|---|---|
| Ecker | 0,05 | 0,03 | 0,03 | 3,50 | 0,26 | 0,02 |
| Grane | 0,12 | 0,09 | 0,09 | 0,13 | 0,11 | 0,01 |
| Innerste | 7,28 | 7,57 | 0,73 | 7,57 | 1,34 | 0,12 |
| Oder | 1,31 | 1,31 | 0,99 | 9,41 | 1,52 | 0,13 |
| Oker | 1,31 | 1,32 | 1,29 | 1,34 | 1,32 | 0,11 |
| Söse | 0,45 | 0,46 | 0,45 | 0,47 | 0,45 | 0,04 |
Es werden demnach momentan etwa 0,43 Millionen Kubikmeter Wasser pro Tag (Höchstwert 8,38 Mio m³ am 27.12.2023) Richtung Oker und Leine, und damit in die Aller und schlussendlich in die Weser geleitet.
Um überhaupt einen gewissen Spielraum für den Hochwasserschutz in Q1 2024 zu haben, musste der Höchststand im Dezember 2023 von etwa 179 Mio m³ signifikant gesenkt, das Stauwasser also über die ersten Monate verstärkt abgelassen werden.
Gegen Ende Februar 2024 fiel der Gesamtfüllstand auf unter 160 Mio m³ ab, und die Unterwasserabgaben wurden im Vergleich zu den Vorwochen auf etwa die Hälfte reduziert. Möglicherweise verschob sich das Hauptaugenmerk der Harzwasserwerke vom Vermeiden neuerer Hochwässer auf den Vorhalt genügend Trinkwassers für mögliche Trockensommer.
Wie auch immer der Betriebsplan für die sechs Talsperren aussehen mag: das Weihnachtshochwasser hat gezeigt, dass die Harzwasserwerke aufgrund des Klimawandels schnell und dynamisch reagieren können müssen, um den Spagat zwischen den beiden Gegenpolen Hochwasserschutz und Trinkwasserversorgung inklusive Niedrigwasseraufhöhung zu bewältigen.
Die Unterwasserabgabe in 2025 fiel geringer als noch in 2023 und 2024 aus, was wahrscheinlich auf den geringen Zufluß, also den geringeren Niederschlag in diesem Jahr zurückzuführen ist.
Das durch die Schneeschmelze Februar 2026 bedingte, etwas höhere Volumen der Innerste- und Odertalsperre wurde durch gesteigerte UW-Abgaben entlastet. Allerdings muss der Füllstand der anderen vier Talsperren als eher niedrig bezeichnet werden, daher ist die summierte UW-Abgabe aller sechs Stauseen nicht sonderlich hoch.
9. Statistische Vergleiche
Zur besseren Vergleichbarkeit habe ich mehrere statistische Kennzahlen der sechs Talsperren in einer Matrix zusammen dargestellt:
| ∅(%I) | Durchschnittlicher Füllungsgrad in Prozent |
|---|---|
| SD(%I) | Standardabweichung Füllungsgrad |
| ∅(N) | Durchschnittlicher Niederschlag in Millimeter pro 24h |
| SD(N) | Standardabweichung vom durchschnittlichen Niederschlag |
| ∅(Z) | Durchschnittlicher Zufluss im Kubikmeter pro Sekunde |
| SD(Z) | Standardabweichung Zufluss |
| ∅(UW) | Durchschnittliche Unterwasser-Abgabe in Kubikmeter pro Sekunde |
| SD(UW) | Standardabweichung Unterwasser-Abgabe |
| CV(Z,I) | Kovarianz Zufluss zum Inhalt |
| CV(N,Z) | Kovarianz Niederschlag zum Zufluss |
| CV(UW,I) | Kovarianz Unterwasser-Angabe zum Inhalt |
Die Kovarianzen können Hinweise geben, ob bei der jeweiligen Talsperre ein positiv linearer Zusammenhang z.B. zwischen Zufluss und Inhalt existiert, ob und inwieweit also bei steigendem Zufluss auch der Inhalt steigt. Man sollte allerdings diese Werte nicht über-interpretieren, da die Meßwerte nicht optimal erfassbar sind, der zeitliche Zusammenhang teils nicht linear und die Meßfrequenz sehr grob ist (Tagesbasis).
Der Wert Niederschlag wird, wie oben erwähnt, nur an der jeweiligen Talsperre direkt, nicht im gesamten Einzugsgebiet gemessen. Zwar korreliert der am Stausee gemessene Wert offensichtlich mit einem Mittelwert des gesamten Einzugsgebietes, die Korrelation Niederschlag zum Zufluss sollte jedoch genau aus diesem Grund mit Bedacht interpretiert werden.
Zum Beispiel würde ein starker, halbtägiger Regenguss als eintägiger, hoher Niederschlag gemessen werden, der resultierende Zufluss sich aber je nach Einzugsgebiet über mehrere Folgetage verteilen, selbst wenn an diesen Tagen kein Niederschlag mehr fallen sollte. Besitzt das Einzugsgebiet zudem noch relevante eigene Speicherkapazität (Moor), kann man eigentlich nur langfristige statistische Relationen bewerten.
In den folgenden Matrixdarstellungen sind die Maximalwerte innerhalb der Spalten in grün und die Minimalwerte in rot gehalten. Die Kreisgrösse deutet in etwa auf die Größe der jeweiligen Kennzahl der jeweiligen Talsperre hin.
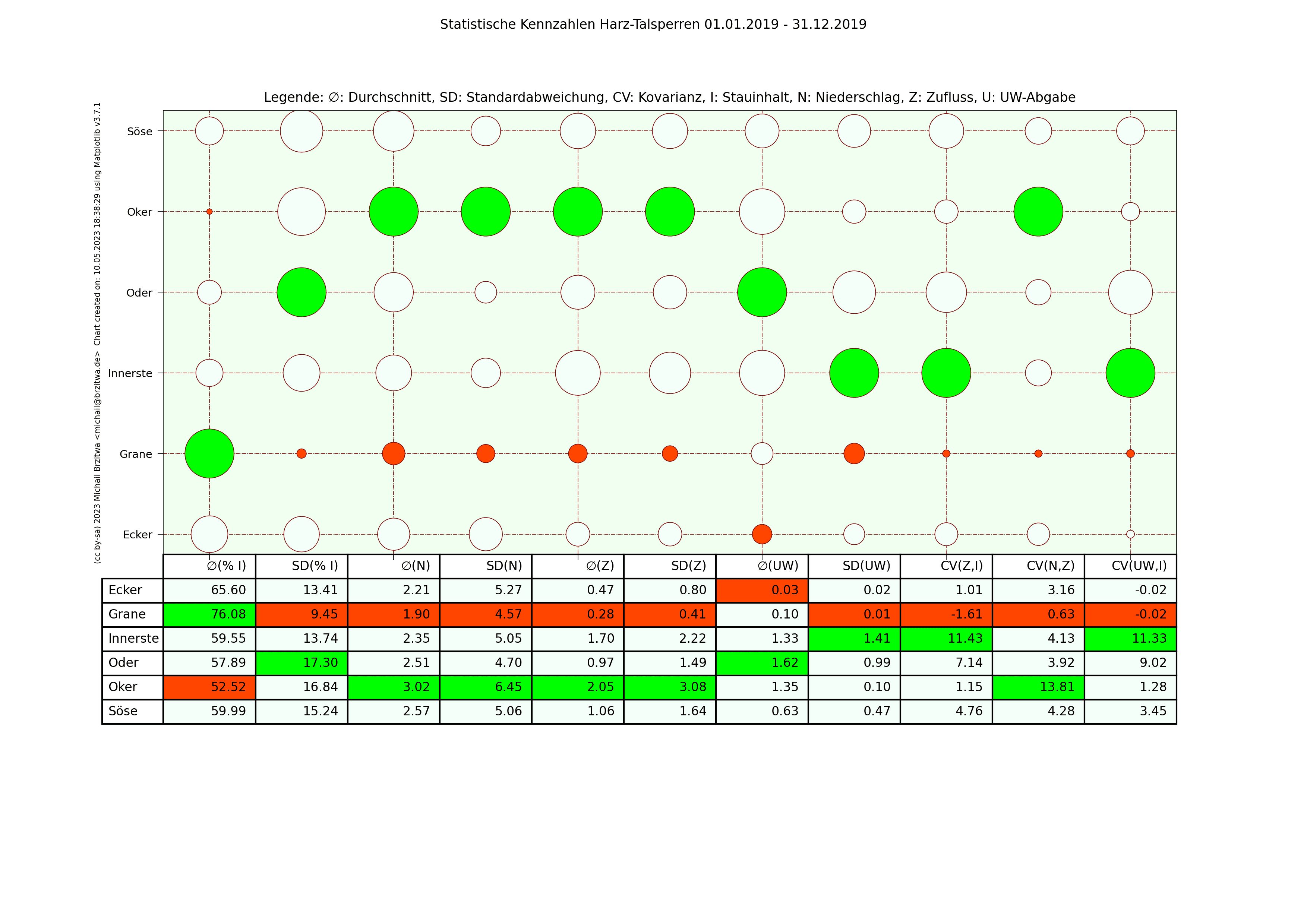
Statistische Kennzahlen Harzer Talsperren 2019
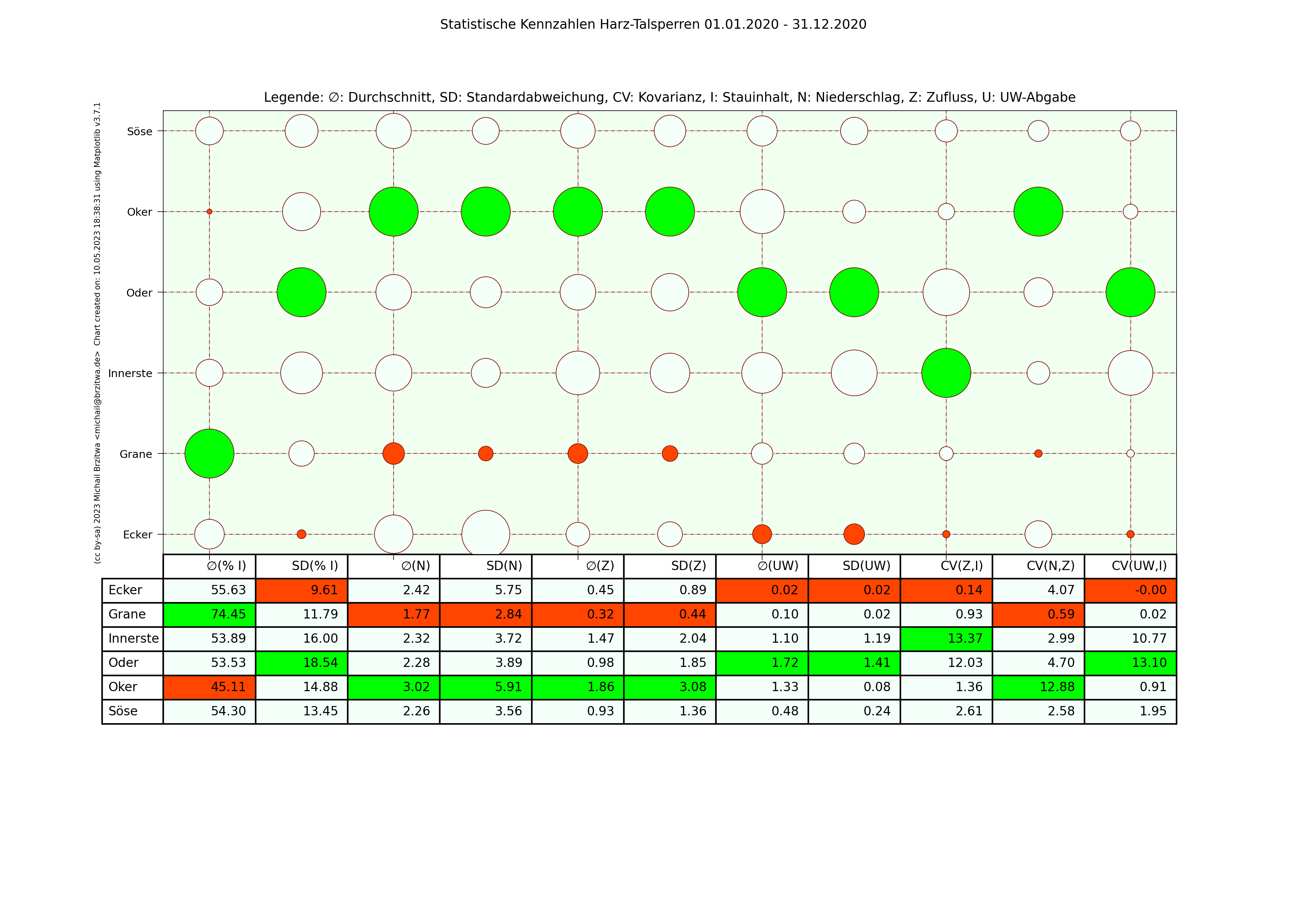
Statistische Kennzahlen Harzer Talsperren 2020
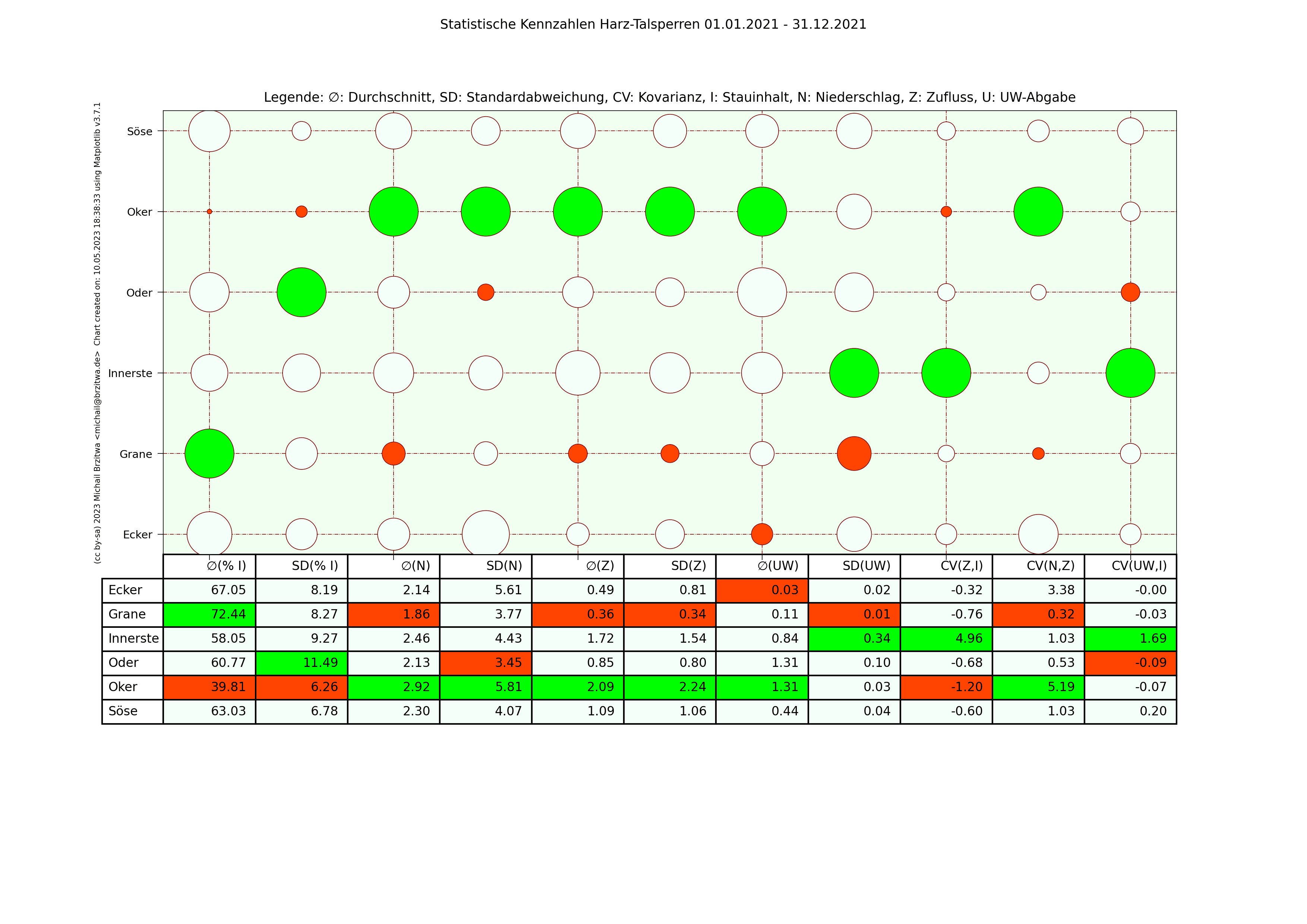
Statistische Kennzahlen Harzer Talsperren 2021
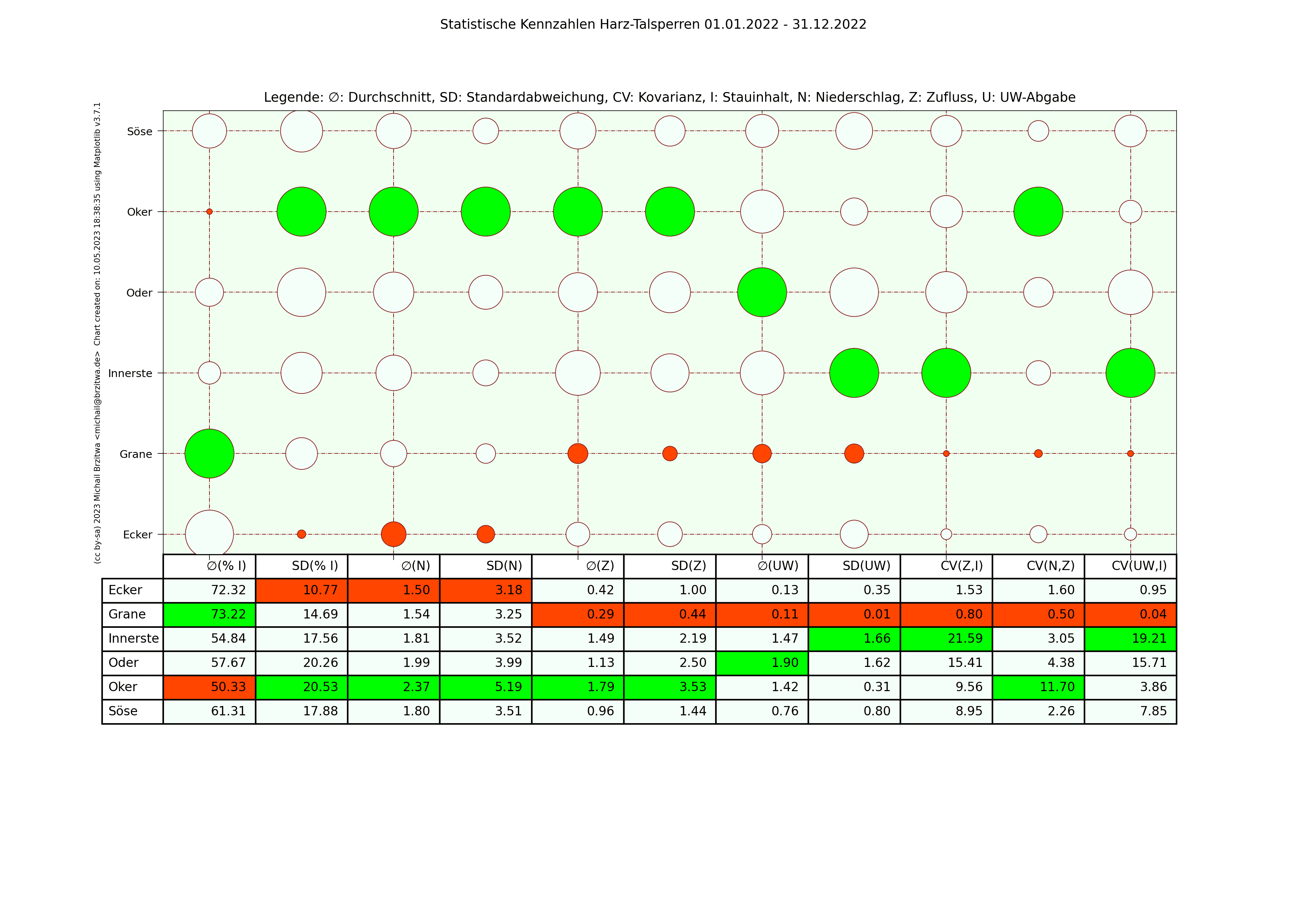
Statistische Kennzahlen Harzer Talsperren 2022
|
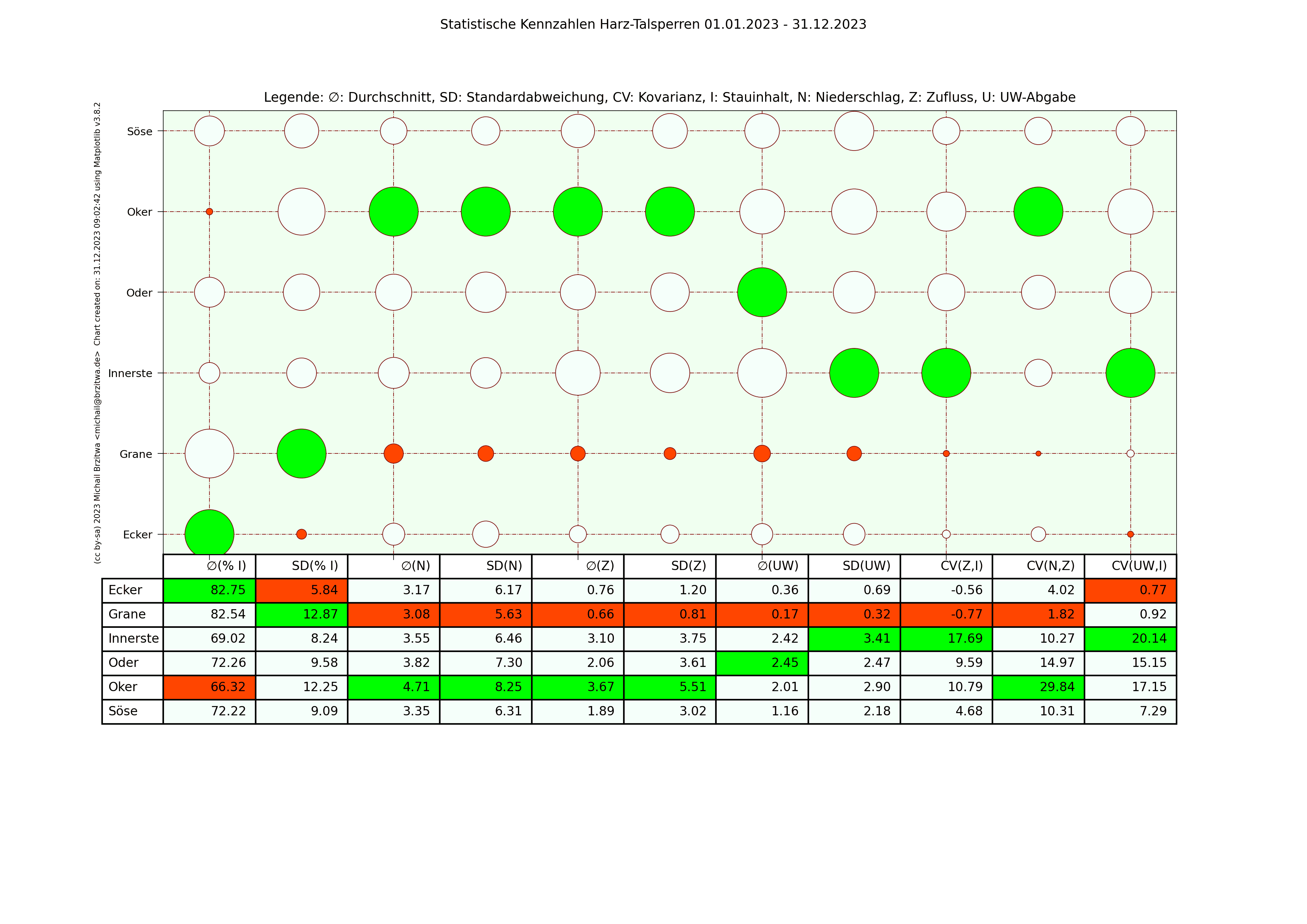
Statistische Kennzahlen Harzer Talsperren 2023
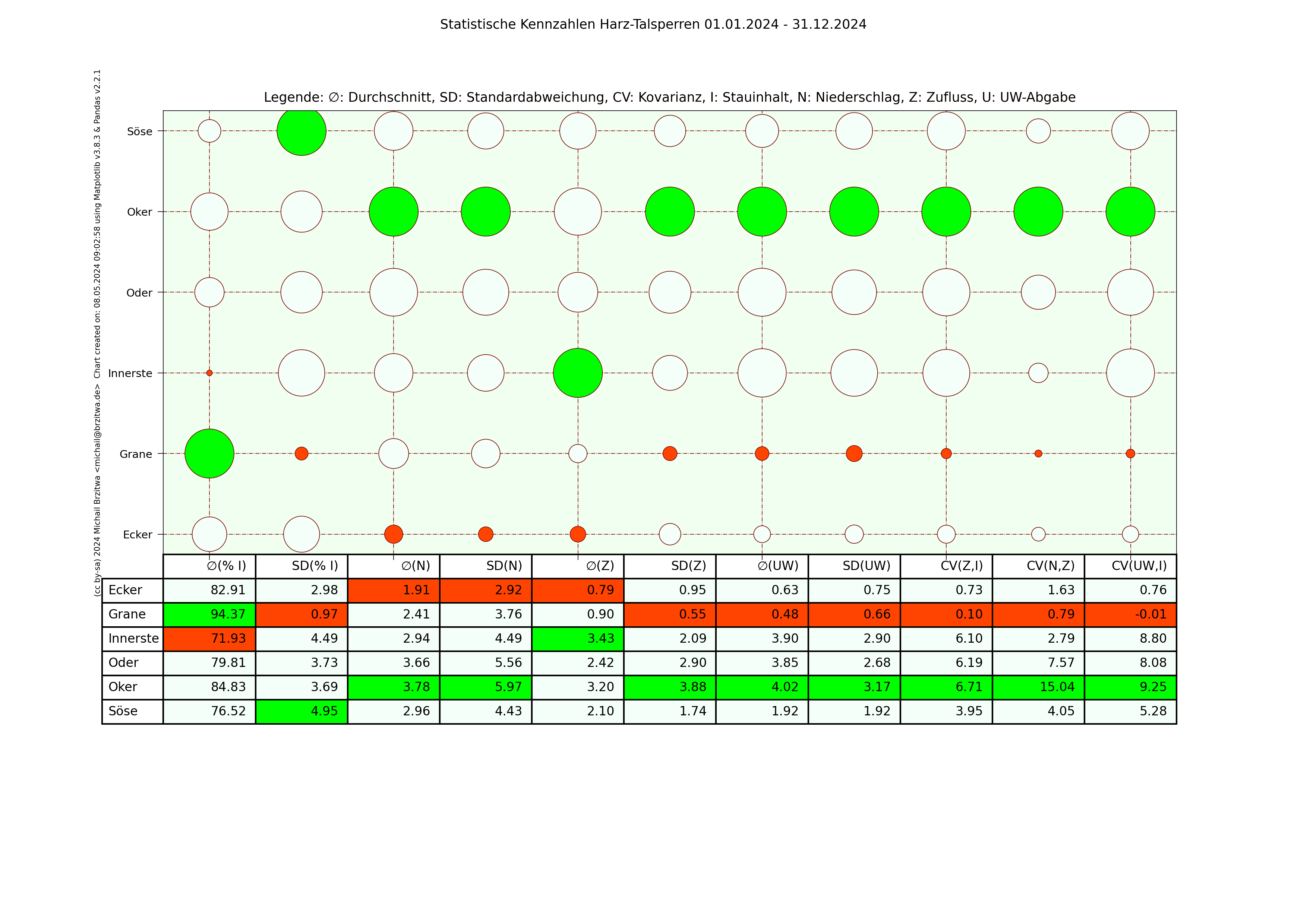
Statistische Kennzahlen Harzer Talsperren 2024

Statistische Kennzahlen Harzer Talsperren 2025
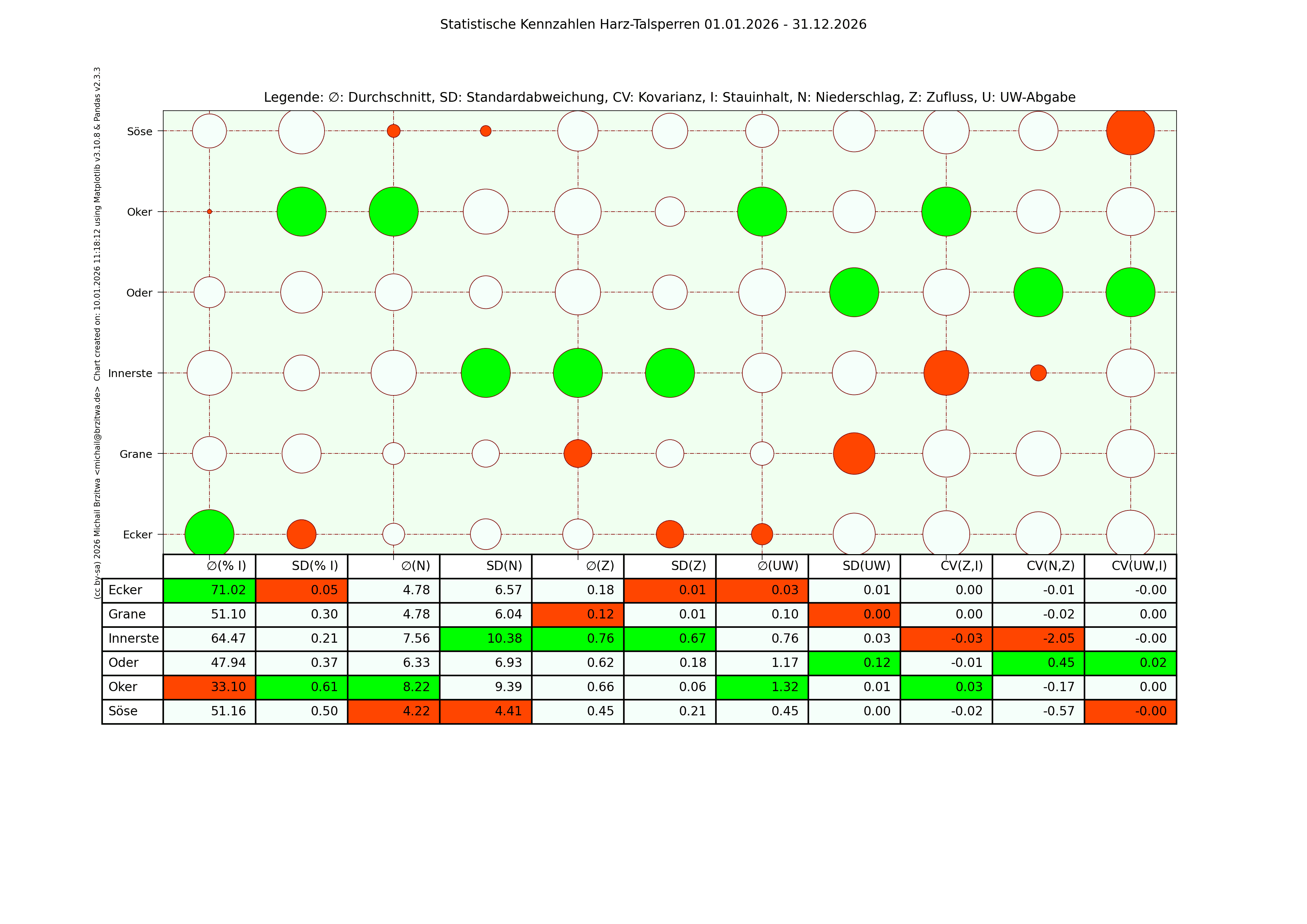
Statistische Kennzahlen Harzer Talsperren 2026
|
Einige Muster werden offenbar: die Okertalsperre weist sowohl den höchsten durchschnittlichen Niederschlag als auch die höchste durchschnittliche Zuflussmenge auf. Gleichzeitig sind ihre Standardabweichungen in beiden Kategorien ebenfalls am höchsten; sie variieren also vergleichsweise am stärksten über den jeweiligen Zeitraum gesehen. Der durchschnittliche Stauinhalt der Okertalsperre ist der niedrigste aller sechs betrachteten Talsperren.
Die Granetalsperre dagegen fast das diametrale Gegenteil der Okertalsperre: Niederschlag und Zufluss der geringste aller Talsperren, eine relativ geringe Abweichung dieser Werte von ihrem Durchschnitt, dafür aber der höchste durchschnittliche Stauinhalt. Die Granetalsperre bezieht Wasser von der Oker- und teilweise der Innerstetalsperre; das erklärt zumindest teilweise, wieso die Granetalsperre die niedrigste Kovarianz Unterwasser-Abgabe zum Inhalt und Niederschlag zum Zufluss besitzt, wieso also der Niederschlag in ihrem Einzugsgebiet nicht oder kaum mit ihrem Zufluss korreliert.
Beide Talsperren haben in etwa den gleichen maximalen Stauinhalt, ein wie oben schon erwähnt sehr unterschiedlich großes Einzugsgebiet, die Höhe über Normalnull der Okertalsperre beträgt 416m, die der Grane 311m. Die abgehenden Flüsse unterscheiden sich ebenfalls wesentlich: die Länge der Oker bis zum Zufluss zur Aller beträgt 128,3km, die der Grane bis zur Innerste 8,9km. Die Oker fliesst durch einige Städte, die Grane mündet noch im Harz selbst in die Innerste, deren Zuflussrate von der Innerstetalsperre aus geregelt werden kann. Die Okertalsperre trägt meiner Ansicht nach also eine weit höhere "Verantwortung" für Hochwasserschutz und Niedrigwasseraufhöhung des nachgeordneten Flusses.
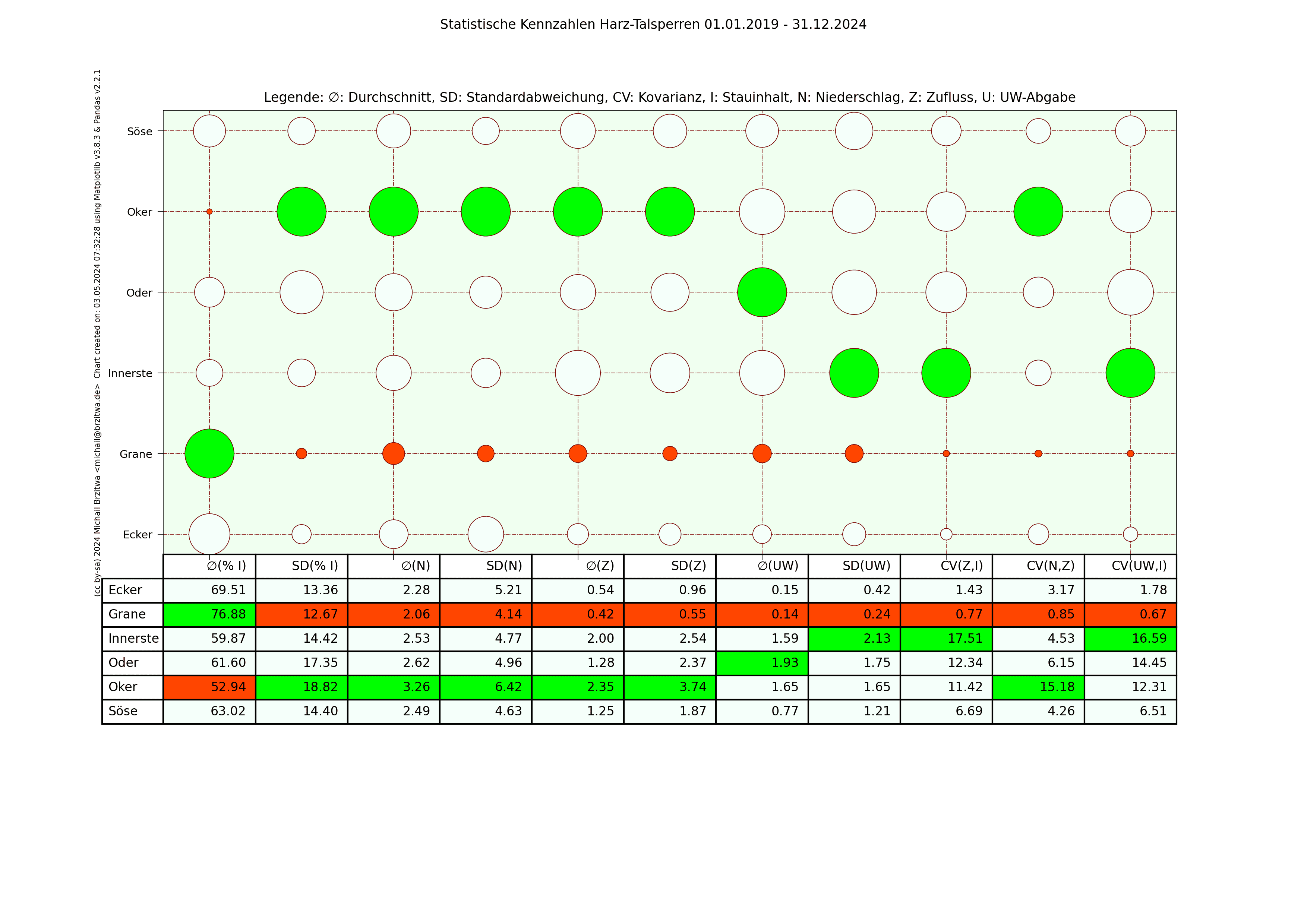
Statistische Kennzahlen Harzer Talsperren 2020 - 2026
|
10. Datenaufbereitung
Die Daten der Talsperren als PDF-Datei werden täglich durch ein Python-Skript heruntergeladen, gesichert, und in einer Instanz der Open Source-Datenbank PostgreSQL gespeichert. Ein weiteres Skript erzeugt dann obige Grafiken.
Die Python-Skripte benötigen vorinstalliert folgende, externen Module:
- PostgreSQL: die freie Datenbank wird manchmal von den jeweiligen Linux-Dialekten standardmäßig mitinstalliert.
- Python Module: psycopg (PostgreSQL), pypdf (PDF Verarbeitung), numpy (Numerik), scipy (Algorithmen), pandas (Datenanalyse) und matplotlib (Plots)
Alle Python-Module sind weit verbreitete Standards, und können z.B. mit dem Paketmanager "pip" ganz einfach heruntergeladen und installiert werden, am Shellprompt z.B. via "pip install psycopg".
Beide Python-Skripte ts_get_data.py und ts_make_charts.py habe ich als Open Source (GPL3) verfasst. Die Datentabellen werden innerhalb PostgreSQL in der Datenbank "postgres", Benutzer "postgres" angelegt. Sollen die Daten woanders gespeichert werden, muss dies auf der Kommandozeile der Skripte (Option "--pgconstr") angegeben, oder direkt im Skript geändert werden. In der DB wird die parent table ts_reservoirs mit den Talsperren-Stammdaten und dem Primärschlüssel der Talsperrennummer angelegt:
create table ts_reservoirs
(
rid integer not null,
name character varying(64) not null,
region character varying(64),
coordinates point,
maxcontent float not null, -- max. volume in 10^6 m³
maxheight float not null, -- max. surface height over NHN
maxarea float not null, -- max. reservoir surface area in km²
basin float not null, -- max. drainage basin area in km²
comments text
);
alter table ts_reservoirs
add constraint pk_ts_reservoirs primary key (rid);
und mit den Stammdaten der sechs Harzer Talsperren initialisiert:
insert into ts_reservoirs (rid,name,region,maxcontent,maxheight,maxarea,basin,coordinates) values (1,'Ecker', 'Harz', 13.27, 557.9, 0.68, 17.0, point(51.835556,10.5875)); insert into ts_reservoirs (rid,name,region,maxcontent,maxheight,maxarea,basin,coordinates) values (2,'Grane', 'Harz', 46.40, 311.0, 2.19, 23.0, point(51.908889,10.374444)); insert into ts_reservoirs (rid,name,region,maxcontent,maxheight,maxarea,basin,coordinates) values (3,'Innerste','Harz', 19.26, 261.0, 1.39, 97.0, point(51.911389,10.284167)); insert into ts_reservoirs (rid,name,region,maxcontent,maxheight,maxarea,basin,coordinates) values (4,'Oder', 'Harz', 30.61, 381.1, 1.36, 52.0, point(51.650556,10.515833)); insert into ts_reservoirs (rid,name,region,maxcontent,maxheight,maxarea,basin,coordinates) values (5,'Oker', 'Harz', 46.85, 416.6, 2.25, 85.0, point(51.851028,10.459139)); insert into ts_reservoirs (rid,name,region,maxcontent,maxheight,maxarea,basin,coordinates) values (6,'Söse', 'Harz', 25.60, 326.5, 1.24, 49.0, point(51.739167,10.326111));
dazu deren child table ts_levels (dort landen alle PDF-Daten):
create table ts_levels
(
rid integer not null,
mtime timestamp not null,
mdate date generated always as (mtime::date) stored, -- 'virtual' from PG16 on
rainfall float not null,
curcontent float not null,
curheight float not null,
influx float not null,
uwefflux float not null,
lastupdate timestamp
);
alter table ts_levels
add constraint fk_ts_levels foreign key (rid) references ts_reservoirs(rid);
alter table ts_levels
add constraint ukey_ts_levels unique (rid,mtime);
und einer kleinen Tabelle der Spezifizierungen obiger Spalten:
create table ts_valuespecs
(
valname character varying(16) not null,
description character varying(64) not null,
uom character varying(16) not null -- unit of measure
);
Mit dem ersten Skript ts_get_data.py können obige Datenbankobjekte vor dem ersten Einlesen angelegt werden:
$> ./ts_get_data.py --initialize WARNING: initializing the DB tables will drop all previously stored reservoir data. Continue (y,n)? y Successfully dropped and created 3 tables and 1 function
Die möglichen Kommandozeilenoptionen beider Skripte können wie gewohnt aufgelistet werden:
$> ./ts_get_data.py --help
usage: ts_get_data.py [-h] [--initialize] [-c] [-d] [-f LOADSINGLE] [-u]
[-s [DATADIR]] [-r [DATAURL]] [-p [PGCONSTR]] [-v] [-V]
Download and store daily Harz reservoir data
optional arguments:
-h, --help show this help message and exit
--initialize Initialize necessary DB structures (default: False)
-c, --checktoday Continue only if there are no entries of today in the
database (default: False)
-d, --download Download current data and store in database (default:
False)
-f LOADSINGLE, --loadsingle LOADSINGLE
Load single data file and store in database (default: None)
-u, --updatedir Update or insert the whole data directory in database
(default: False)
-s [DATADIR], --datadir [DATADIR]
Set data directory (default: Harzwasserwerke)
-r [DATAURL], --dataurl [DATAURL]
Data url to download (default:
https://www.harzwasserwerke.de/talis/hochwasserdaten.pdf)
-p [PGCONSTR], --pgconstr [PGCONSTR]
PostgreSQL connection string (default: dbname=postgres
user=postgres)
-v, --verbose Be more talkative (default: False)
-V, --version Show script version and exit (default: False)
Die aktuelle PDF-Datei der Harzwasserwerke herunterladen, im Downloadverzeichnis sichern und die Talsperren-Werte in der DB speichern:
$> ./ts_get_data.py --download
Voreinstellung des Downloadverzeichnisses ist "Harzwasserwerke" im lokalen Verzeichnis. Wurden die DB-Tabellen neu angelegt, oder alte PDFs direkt in das Downloadverzeichnis gestellt, kann der Inhalt aller dort liegenden PDFs in die DB geladen werden:
$> ./ts_get_data.py --updatedir
Bestehende DB-Einträge werden nicht gelöscht, sondern gegebenenfalls geupdated.
Die eigentliche Erzeugung der Grafiken geschieht durch das zweite Skript ts_make_charts.py. Es erzeugt per Voreinstellung DIN A4 Grafikdateien im PNG-Format. Keine Web-Darstellung (Javascript-Klassen zur Einbettung), da diese bezüglich einer Skalierbarkeit Raster- oder Vektor-Grafikdateien eher unterlegen sind; ein schneller 1200dpi Ausdruck auf DIN A3 (Kommandozeilenoption: "ts_make_charts.py -x 420 -y 297 -d 1200", braucht zweistellig GB Ram, wenn Bitmaps gewünscht sind!) oder eine sinnvolle Darstellung auf einem 50" Monitor kann man meist komplett knicken.
Die Grafiken können entweder für den gesamten Erfassungszeitraum oder das aktuelle Jahr erzeugt werden. Mögliche Kommandozeilenparameter:
$> ./ts_make_charts.py --help
usage: ts_make_charts.py [-h] [-c [CHARTSDIR]] [-b [BGIMAGE]] [-d [DPI]]
[-f [IMAGEFORMAT]] [-m] [-p [PGCONSTR]] [-s] [-t]
[-x [XFIGSIZE]] [-y [YFIGSIZE]] [-v] [-V]
Create Harz reservoir data charts
optional arguments:
-h, --help show this help message and exit
-c [CHARTSDIR], --chartsdir [CHARTSDIR]
Set charts directory (default: Harzwasserwerke/Charts)
-b [BGIMAGE], --bgimage [BGIMAGE]
Set chart background image to file (default: None)
-d [DPI], --dpi [DPI]
Set charts image resolution in dpi (default: 300)
-f [IMAGEFORMAT], --imageformat [IMAGEFORMAT]
Set charts image format (jpg, png, svg, ...) (default: png)
-m, --nominmax Do not show min/max comments on chart (default: False)
-p [PGCONSTR], --pgconstr [PGCONSTR]
PostgreSQL connection string (default: dbname=postgres
user=postgres)
-s, --nosumming Do not show summed values in charts (default: False)
-t, --thisyear Recreate charts just for the current year (default: False)
-x [XFIGSIZE], --xfigsize [XFIGSIZE]
Image width (landscape) in mm (default: 297)
-y [YFIGSIZE], --yfigsize [YFIGSIZE]
Image height (landscape) in mm (default: 210)
-v, --verbose Be more talkative (default: False)
-V, --version Show script version and exit (default: False)
Ein tägliches Update (automatisch dann via cron-job, dort natürlich ohne -v) sieht hier so aus:
$> ./ts_get_data.py -vd && ./ts_make_charts.py -vt Connected to: PostgreSQL 15.6 (Debian 15.6-0+deb12u1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 12.2.0-14) 12.2.0, 64-bit Downloaded "/home/mb/src/python/talsperren/Harzwasserwerke/Talsperrendaten.pdf" Entry of 2024-05-23 05:00:00: Ecker,4.0,555.23,11.51,0.58,0.02 Entry of 2024-05-23 05:00:00: Grane,2.0,309.83,43.87,0.21,0.11 Entry of 2024-05-23 05:00:00: Innerste,6.0,255.23,12.16,0.85,0.75 Entry of 2024-05-23 05:00:00: Oder,7.0,373.89,21.82,0.8,2.19 Entry of 2024-05-23 05:00:00: Oker,7.0,411.01,35.39,2.35,1.51 Entry of 2024-05-23 05:00:00: Söse,6.0,321.09,19.34,0.83,0.45 Files read: 1, skipped: 0, records processed: 6, time: 0:00:00.238230 Connected to: PostgreSQL 15.6 (Debian 15.6-0+deb12u1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 12.2.0-14) 12.2.0, 64-bit Creating summarized charts for 2024... Creating single reservoir charts for 2024... Creating yearly difference charts for 2024... Creating daily difference charts for 2024... Creating statistics charts for 2024... Charts created: 24, time: 0:02:30.810743
Die Abszisse (x-Achse) der Graphen enthält fast immer die Zeit in Tagesauflösung. Da einige Meßtage fehlen (kaum Daten an Wochenenden, ich hab's verpennt, Urlaub usw.), werden vor dem Erzeugen der Grafiken und Statistiken die Werte an nicht gegebenen Tagen linear interpoliert. Das Skript liest die erforderlichen Daten aus der Datenbank, erzeugt daraus pandas DataFrames und stellt diese mit den Möglichkeiten der Python matplotlib dar.
Seit Anfang 2023 werden die tagesweisen Vergleiche der Jahresgesamtstände täglich auf Twitter gepostet.
Das Posten geschieht wiederum durch einen Python-Skript ts_tweet_chart.py, das zwecks Twitter-Authentifikation noch eine Konfigurationsdatei ts_tweet_chart.json benötigt, die zwei Twitter-Accesstokens inklusive zugehöriger Schlüssel enthält.
11. Disclaimer
Alle hier gemachten Angaben und Auswertungen ohne jegliche Gewähr der Korrektheit. Die von der Harzwasserwerke GmbH übernommenen Daten sind von dieser GmbH oder anderer Seite weder geprüft noch verifiziert.
Alle hier gemachten Aussagen über Stände, Entwicklungen und Bewertungen basieren ausschließlich auf diesen Tagesdaten der Harzwasserwerke GmbH, keine anderen Quellen wurden verwendet.
12. Kontakt
Bitte old-school nur über untenstehende Email-Adresse.
Die Datenbasis (PDF-Tagesdaten der Harzwasserwerke GmbH 2018 bis heute) kann ich auf Anfrage zur Verfügung stellen.